奥特曼深夜发动价格战,GPT-4o mini暴跌99%!清华同济校友立功,GPT-3.5退役
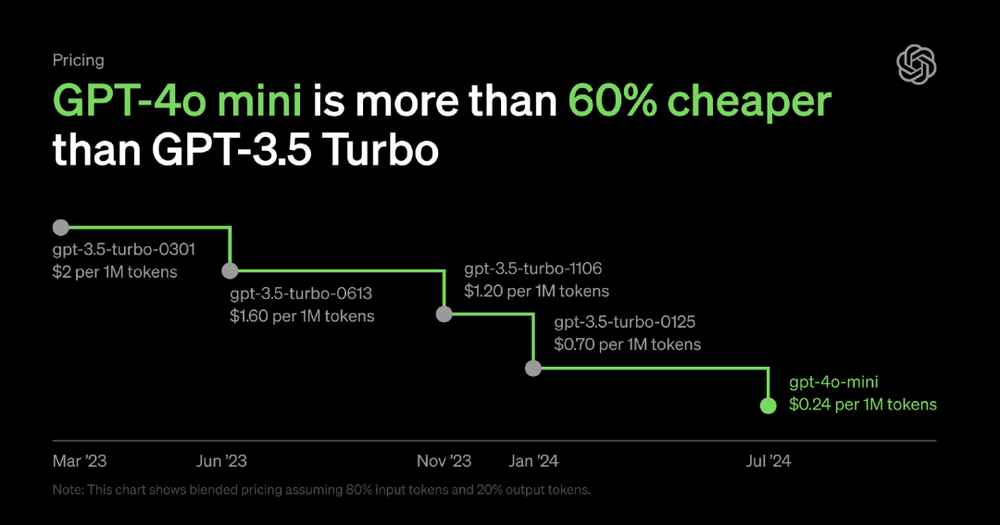
奥特曼深夜发动价格战,GPT-4o mini暴跌99%!清华同济校友立功,GPT-3.5退役GPT-4o mini深夜忽然上线,OpenAI终于开卷小模型!每百万输入token已达15美分的超低价,跟GPT-3相比,两年内模型成本已降低99%。Sam Altman惊呼:通往智能的成本,已变得如此低廉!另外,清华同济校友为关键负责人。
来自主题: AI资讯
10498 点击 2024-07-19 12:09