苹果再发论文:精准定位LLM幻觉,GPT-5、o3都办不到
苹果再发论文:精准定位LLM幻觉,GPT-5、o3都办不到论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。
来自主题: AI资讯
9835 点击 2025-10-07 22:11
 搜索
搜索
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。

AI又又又帮陶哲轩解决了一个难题!消息来自陶本人最新发帖,他直言不讳地表示:甚至,如果没有AI,他也不会决定采用目前已经取得成功的关键策略。
奥特曼在一期访谈中,表示ChatGPT从1到10的艰难过程已过去,接下来从10到100可能会容易很多。除此之外,奥特曼也为我们揭秘了ChatGPT是如何诞生的,以及OpenAI的未来愿景等问题。

Agent(智能体)是最近一段时间的人工智能热点之一,将大语言模型的能力与工具调用、环境交互和自主规划结合起来,使其能够像虚拟助理一样完成复杂任务。 其中「计算机使用智能
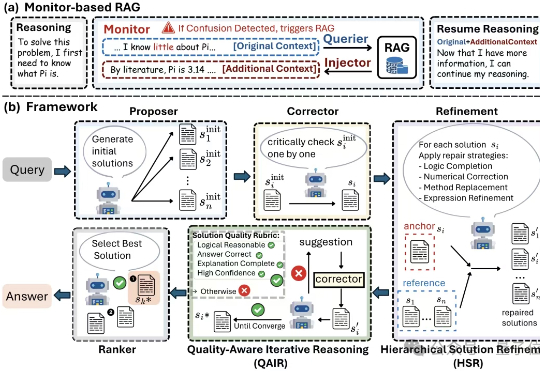
就在最近,由耶鲁大学唐相儒、王昱婕,上海交通大学徐望瀚,UCLA万冠呈,牛津大学尹榛菲,Eigen AI金帝、王瀚锐等团队联合开发的Eigen-1多智能体系统实现了历史性突破

今年 8 月,GPT-5 发布,其在多个任务和基准上都表现卓越,但几乎和人世间的所有事物一样,并不是所有人都满意。尤其是 GPT-5 发布后「OpenAI 移除 ChatGPT 中模型选择器」的做法更是备受诟病(尤其是移除了情感表达更佳的 GPT-4o),甚至引发了诸多用户的「网上请愿」,详见我们的报道《用户痛批 GPT-5,哭诉「还我 GPT-4o」,奥特曼妥协了》。
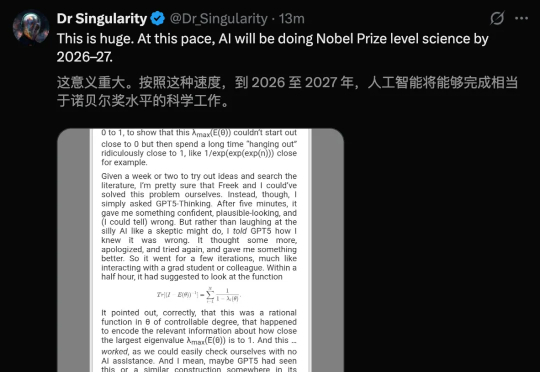
GPT-5正改写科学发现的规则!一篇重磅论文揭秘,「量子版NP难题」竟被GPT-5在30分钟之内攻克了,然而这要耗费人类1-2周的时间。照这种速度发展下去,AI离完成「诺奖级」突破真的不远了。
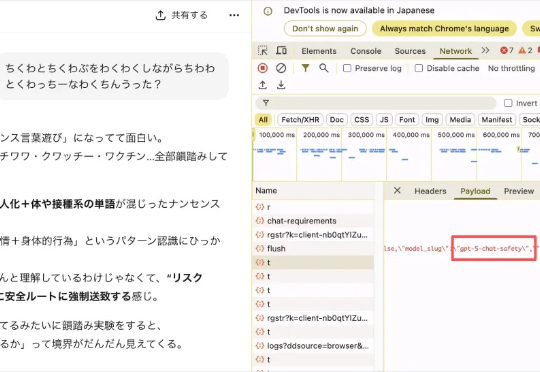
我用ChatGPT越来越少了,即使他有记忆的情况下,我还是非常非常的不喜欢GPT-5。 因为在很多话题的质量上,现在跟Gemini 2.5 Pro相比,几乎就是一坨。 但是作为一个自媒体博主,为了有时
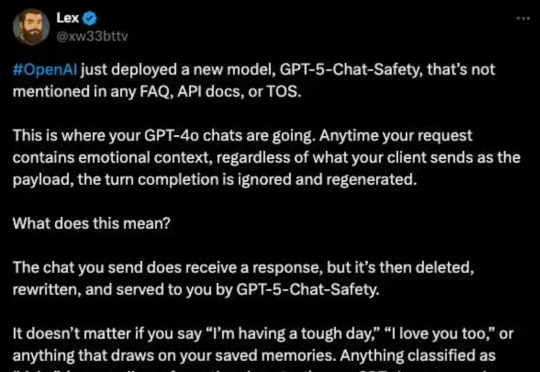
OpenAI被曝在用户不知情下,强制将GPT-4、GPT-5等模型路由至两款低算力敏感模型「gpt-5-chat-safety」与「gpt-5-a-t-mini」,导致回复被过滤或替换,引发用户对选择权和付费权益的质疑。该现象已在社交媒体广泛验证。

GPT-5,你这家伙! 究竟还有什么事是我不知道的? 在一篇最新论文中,研究人员让它挑战了5个尚未解决的优化猜想。 结果它居然解出了其中3个!