憋了4个月,阿里最大最强模型Qwen3-Max-Thinking正式版发布!附一手实测
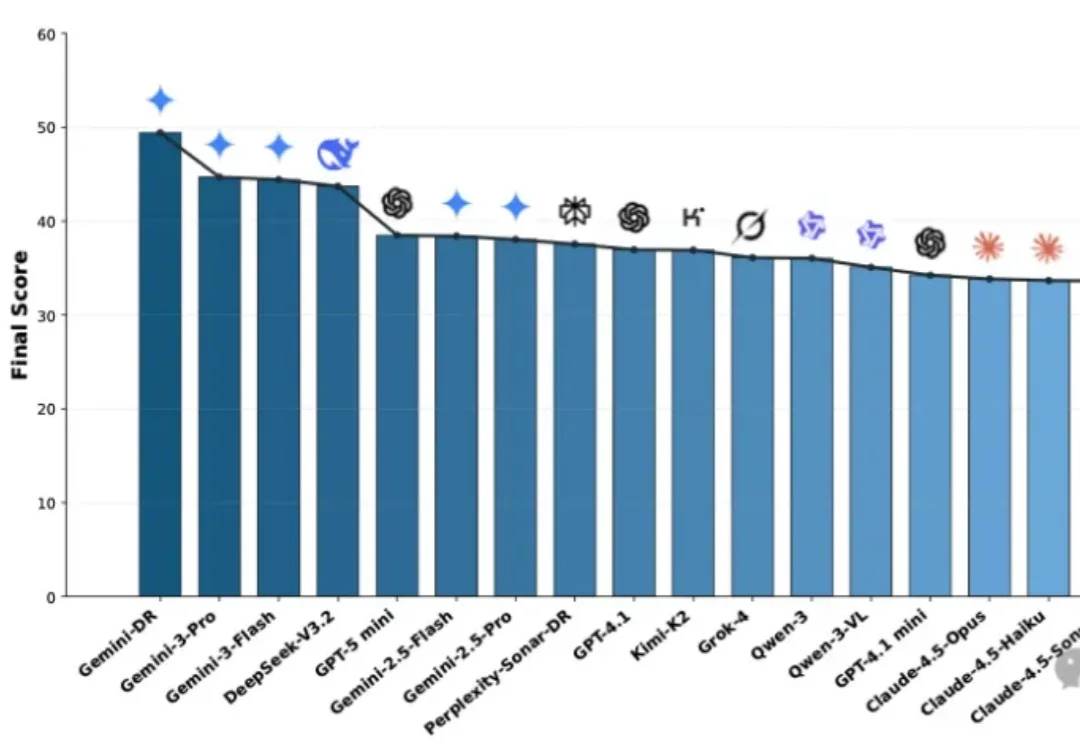
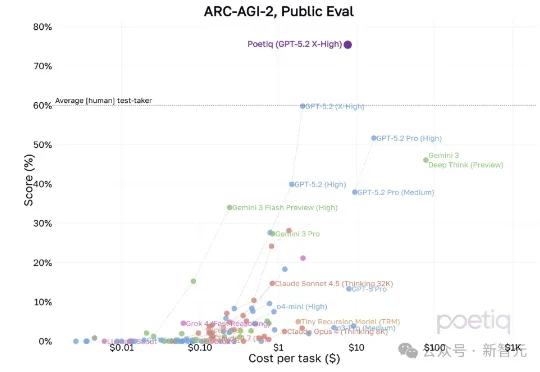
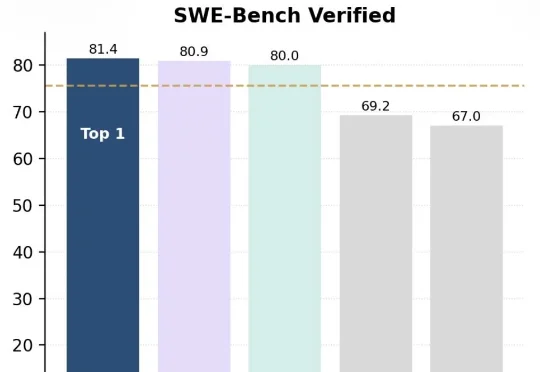
憋了4个月,阿里最大最强模型Qwen3-Max-Thinking正式版发布!附一手实测阿里巴巴推出了Qwen3-Max-Thinking,这是阿里千问系列目前能力最强的旗舰级推理模型,在19项权威基准测试中,Qwen3-Max-Thinking跟GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等顶尖模型打得有来有回,搭配测试时扩展(TTS)能力后,能在不少基准测试上达到SOTA。
来自主题: AI资讯
10362 点击 2026-01-27 11:21