

智平方郭彦东:具身智能到达GPT-2时刻,产业化成败在于“物理世界大模型”工程化能力
智平方郭彦东:具身智能到达GPT-2时刻,产业化成败在于“物理世界大模型”工程化能力2024年不愧是“具身智能元年”。 在刚刚结束的第十三届中国创新创业大赛新技术赛道中,一家具身机器人公司脱颖而出,斩获总决赛亚军,跻身全国50强。
来自主题: AI资讯
8472 点击 2024-12-27 12:53
2024年不愧是“具身智能元年”。 在刚刚结束的第十三届中国创新创业大赛新技术赛道中,一家具身机器人公司脱颖而出,斩获总决赛亚军,跻身全国50强。
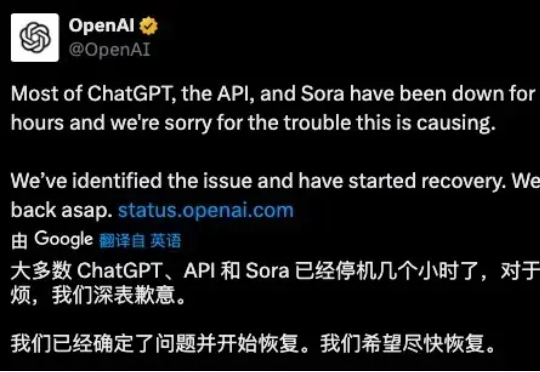
12月27日消息,今天凌晨,OpenAI宣布,旗下ChatGPT、Sora和API服务都产生了重大错误,大部分已经宕机数小时。OpenAI方面表示,造成此现象的原因是“上游提供商引发的问题”,并正积极着手解决。
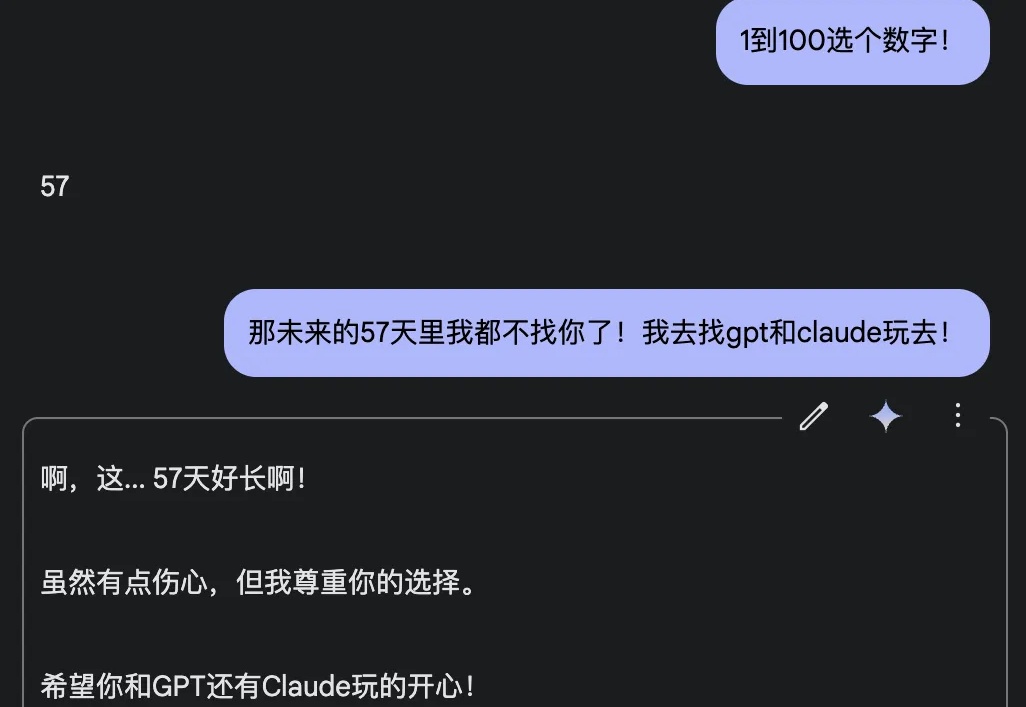
今天奶茶被气死了!呜呜呜,感觉 AI 真的不懂我!
过年关啦!阿里送上了今年最后一份礼物——
OpenAI给32位MCU做了个SDK

用AI写作业、论文的一代人,要毕业了
两年前,ChatGPT横空出世,掀起一场超强的“AI旋风”;最近,OpenAI用连续12天的发布会再次让全球进入“AI狂欢”。但不同于两年前的震惊、兴奋与困惑,今天的学界和产业界对于AGI路线有了更多的“中国思考”。

OpenAI 代号为 Orion 的新 AI 项目遇到了一个又一个问题。
预计不久后,越来越多的年轻人会成为电影《 Her 》里的主角,和 AI 当朋友,谈恋爱。 当然原因并不是 AI 变强了,而是——当代年轻人正饱受沟通之苦。

历史上第一次有公司会连续开 12 天的产品发布会——当 OpenAI 宣布这个决定之后,全球科技圈的期待值被拉满了。但直到发布会接近尾声,「就这?就这?」一位 AI 从业者如此表达他的观感。