

OpenAI日本CEO透露GPT-Next性能将比GPT-4提升100倍
OpenAI日本CEO透露GPT-Next性能将比GPT-4提升100倍在2024年KDDI峰会上,OpenAI日本首席执行官Tadao Nagasaki宣布了一项吸引业界的消息:OpenAI的最新人工智能模型——GPT-Next——即将问世,其性能预计将比现有的GPT-4强大100倍。
来自主题: AI资讯
11009 点击 2024-09-10 21:19
在2024年KDDI峰会上,OpenAI日本首席执行官Tadao Nagasaki宣布了一项吸引业界的消息:OpenAI的最新人工智能模型——GPT-Next——即将问世,其性能预计将比现有的GPT-4强大100倍。

高盛一张关于“ChatGPT访问量跳水”的图,一度引发大范围恐慌。但最终被证明不过是虚惊一场。
继OpenAI在5月发布会上展示「期货」GPT-4o的语音功能后,「AI语音助手」类的产品又成为了硅谷科技巨头的必争之地。

Sora深陷研究困境? Sora在今年二月发布后,至今还是「期货」,为何迟迟不开放呢

Sam Altman拿了这么多各路神仙的钱后,会不会也为了“回购”而睡不着觉?

由AI生成的内容渐渐充斥了互联网。

不是 AI 无处不在,而是 AI 可穿戴设备无处不在。
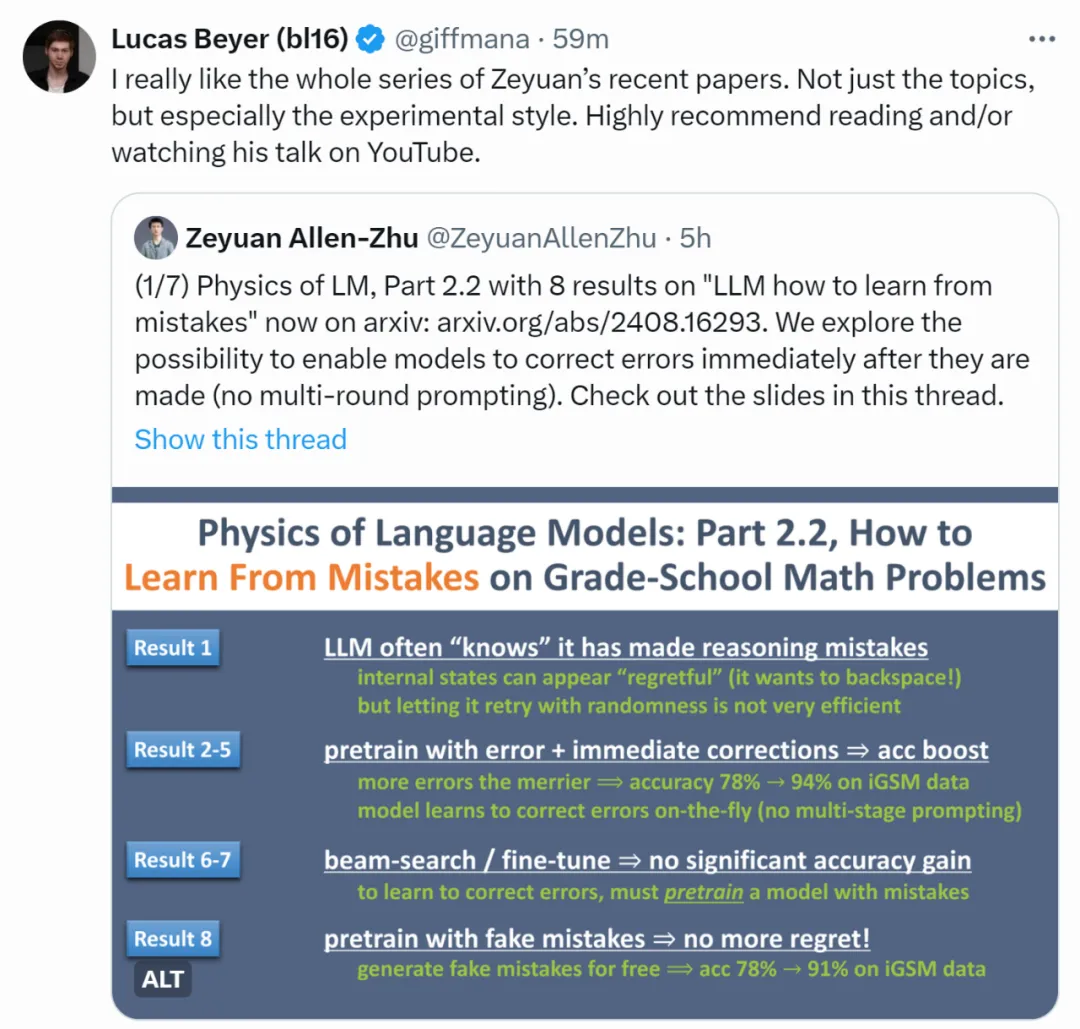
即便是最强大的语言模型(LLM),仍会偶尔出现推理错误。除了通过提示词让模型进行不太可靠的多轮自我纠错外,有没有更系统的方法解决这一问题呢?

「卖铲人」英伟达股价又又又跌了。

宾夕法尼亚大学苏炜杰教授团队在ICML 2023会议中进行实验显示,经过作者自评校准后,审稿分数的误差降低超过20%。