

这个最懂人心的爆火 AI 也要倒下了?
这个最懂人心的爆火 AI 也要倒下了?Character AI 也要走上 Stability AI 的老路了?
来自主题: AI资讯
5451 点击 2024-07-03 14:37
Character AI 也要走上 Stability AI 的老路了?
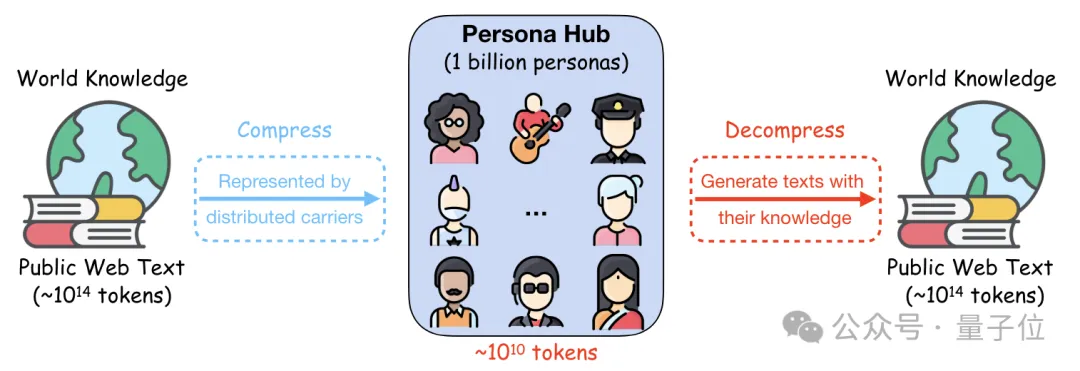
10亿名“员工”生产数据合成,数量占到了世界人口的13%。

「微调你的模型,获得比GPT-4更好的性能」不只是说说而已,而是真的可操作。最近,一位愿意动手的ML工程师就把几个开源LLM调教成了自己想要的样子。

中国的大模型已经在春天了。

本文研究发现大语言模型在持续预训练过程中出现目标领域性能先下降再上升的现象。

数字化转型,不仅仅是企业的数字化,组织的数字化,流程的数字化,更是人的数字化。

AI 产品刷屏后,你的工作和生活是否因此发生了一些变化。

来看看五位商界领袖怎么说

从智能眼镜,到AI眼镜。

什么?好多大模型的文科成绩超一本线,还是最卷的河南省???