Sora和ChatGPT之后,教育怎么办?
Sora和ChatGPT之后,教育怎么办?用过ChatGPT的人知道,新时代来临了。Sora的出现,将人工智能推向新高潮。
来自主题: AI技术研报
7611 点击 2024-02-29 13:17
 搜索
搜索
用过ChatGPT的人知道,新时代来临了。Sora的出现,将人工智能推向新高潮。

说ChatGPT是AI的iPhone时刻有些言过其实, AGI的路上少不了Hugging Face…

Coze 是字节出海的产品,访问地址为 coze.com,扣子是字节2月1日在国内上线的产品,访问地址为 coze.cn,
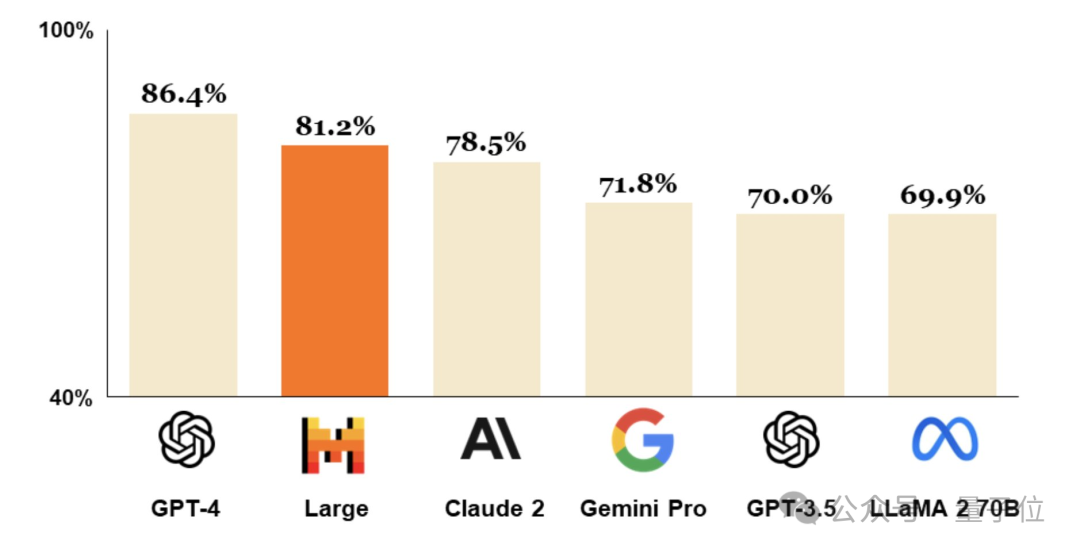
成立仅9个月,法国Mistral AI拿出仅次于GPT-4的大模型。

近日,有报道称,AI 技术的先驱——OpenAI 正在开发一款集成或可能独立的网络搜索产品,这一举措预示着 AI 在搜索技术中的角色将被进一步加强。

《纽约时报》诉OpenAI侵犯版权索赔数十亿美元案最新进展:在最新提交的法庭文件中,OpenAI声称《纽约时报》花钱找黑客攻击ChatGPT,人为制造侵权结果。

随着大语言模型(LLMs)在近年来取得显著进展,它们的能力日益增强,进而引发了一个关键的问题:如何确保他们与人类价值观对齐,从而避免潜在的社会负面影响?

谷歌DeepMind最新研究发现,问题中前提条件的呈现顺序,对于大模型的推理性能有着决定性的影响,打乱顺序能让模型表现下降30%。

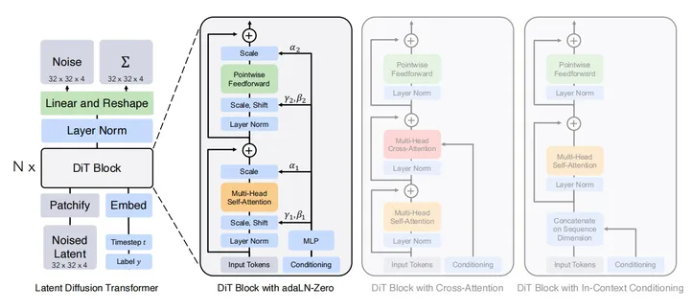
2022年底,OpenAI推出人工智能聊天机器人ChatGPT,开启了大模型领域的“竞速跑”模式。2024年2月15日,随着视频生成模型Sora的横空出世,OpenAI再度掀起热潮。
「从头开始构建GPT分词器」文字版来了。