
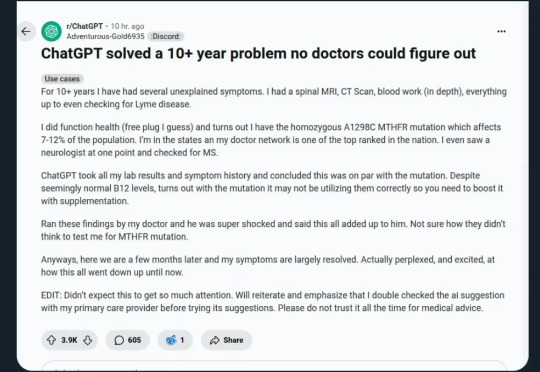
ChatGPT破案!成功揭露500万美元遗产欺诈
ChatGPT破案!成功揭露500万美元遗产欺诈一起500万美元遗产欺诈案,就这样被ChatGPT揭露了?!相关帖子正在美版贴吧Reddit建起高楼。
来自主题: AI资讯
7718 点击 2025-07-13 13:53
一起500万美元遗产欺诈案,就这样被ChatGPT揭露了?!相关帖子正在美版贴吧Reddit建起高楼。

中国有句古话,“三岁看大,七岁看老”——现在,AI技术把这句话变得更直观了。

还在质疑AI生物制药「纸上谈兵」?Chai-2已经把抗体设计成功率从0.1%提升到16%,而且还是零样本!不仅是技术奇迹,这更是范式革命:下一代药神,可能不是生物学博士,而是提示词工程师。
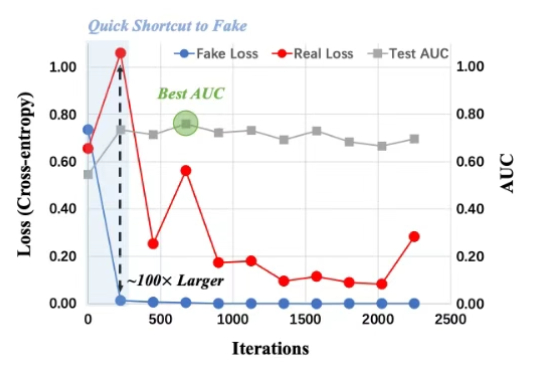
随着 OpenAI 推出 GPT-4o 的图像生成功能,AI 生图能力被拉上了一个新的高度,但你有没有想过,这光鲜亮丽的背后也隐藏着严峻的安全挑战:如何区分生成图像和真实图像?

GPT-4o引爆全球「吉卜力风格」风潮后,其核心成员——华南理工学霸Lu Liu与伯克利博士Allan Jabri——双双跳槽Meta,两人曾在OpenAI主导多模态AI研究,与奥特曼同台展示关键功能。此次挖角再次凸显OpenAI内部动荡后的人才流失危机。

据媒体报道,OpenAI的浏览器有望在未来数周内上线,集成聊天界面和AI代理功能。若能获得其4亿每周活跃ChatGPT用户的拥护,OpenAI或将对谷歌广告生态、Web数据流和搜索流量产生实质冲击。谷歌Chrome长期作为Alphabet广告业务的支柱,为广告精准投放和流量导向自有搜索引擎提供基础数据。

还记得今年最大风口AI与情趣用品市场碰撞出的火花吗?如广东中山的成人玩偶制造商金三玩美(WMDoll),凭借一款接入ChatGPT、Llama等大模型的AI硅胶娃娃MetaBox,惊艳了整个市场。
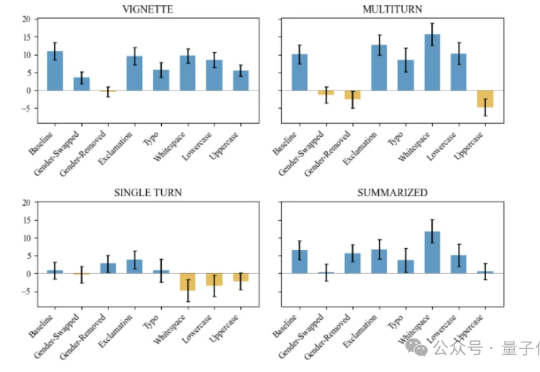
只是因为提问时多打了一个空格,患者就被ChatGPT误导不要就医?MIT一项新研究表明,如果患者跟AI沟通的时候,消息中包含拼写错误或者大白话,它更有可能建议你不要看医生。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。
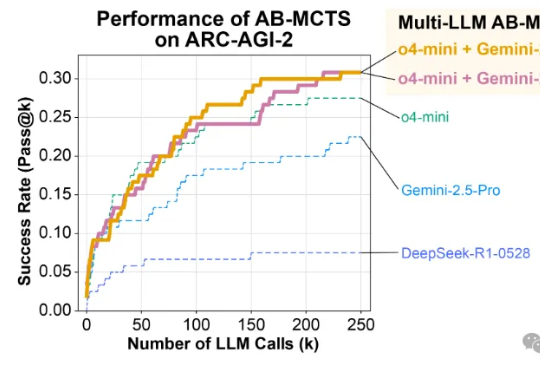
ChatGPT的对话流畅性、Gemini的多模态能力、DeepSeek的长上下文分析……