
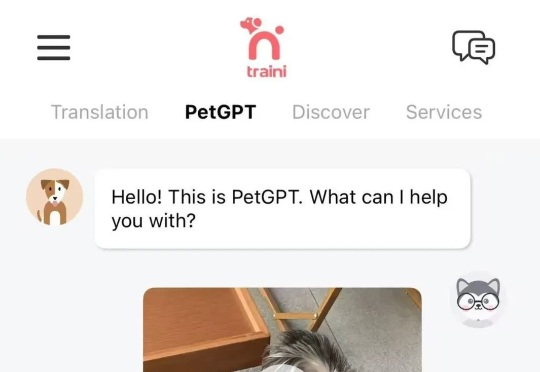
全球首个AI人狗交流软件来了!“将宠物犬行为和叫声翻译成人类语言的准确率已达81.5%”
全球首个AI人狗交流软件来了!“将宠物犬行为和叫声翻译成人类语言的准确率已达81.5%”将自己的宠物犬的照片、视频或是叫声发给Traini,这款App会即刻根据宠物专家给出的专业知识,分析出狗狗想要表达的内容,用人类语言表达出来;同时,也可以将主人的指令翻译成犬吠声,以此达到与自己宠物的“无障碍”交流。
来自主题: AI资讯
11535 点击 2025-04-19 23:25
将自己的宠物犬的照片、视频或是叫声发给Traini,这款App会即刻根据宠物专家给出的专业知识,分析出狗狗想要表达的内容,用人类语言表达出来;同时,也可以将主人的指令翻译成犬吠声,以此达到与自己宠物的“无障碍”交流。
知道大模型接下来要卷视觉推理,但没想到这么卷——数学试卷都快要不够用了。

一股由ChatGPT引爆的AI玩偶热潮正在席卷全球社交媒体!从领英到TikTok,人人都在将自己变成可爱玩偶,搭配个性配饰,装进精美包装盒。你准备好了吗?
“史上最强视觉生成模型”,现在属于快手。一基双子的可灵AI基础模型——文/图生图的可图、文/图生视频的可灵,都重磅升级到2.0版本。可图2.0,对比MidJourney 7.0,胜负比「(good+same) / (same+bad)」超300%,对比FLUX超过150%;

不止GPT-4o可以制作吉卜力风格图像!更多工具都可以制作吉卜力风图像。甚至2分钟之内,还能用照片生成吉卜力风格动画:蒙娜丽莎给你说Hello。
仅隔一天,OpenAI再次突然放大招: 一口气,o3和o4 mini同步上线。
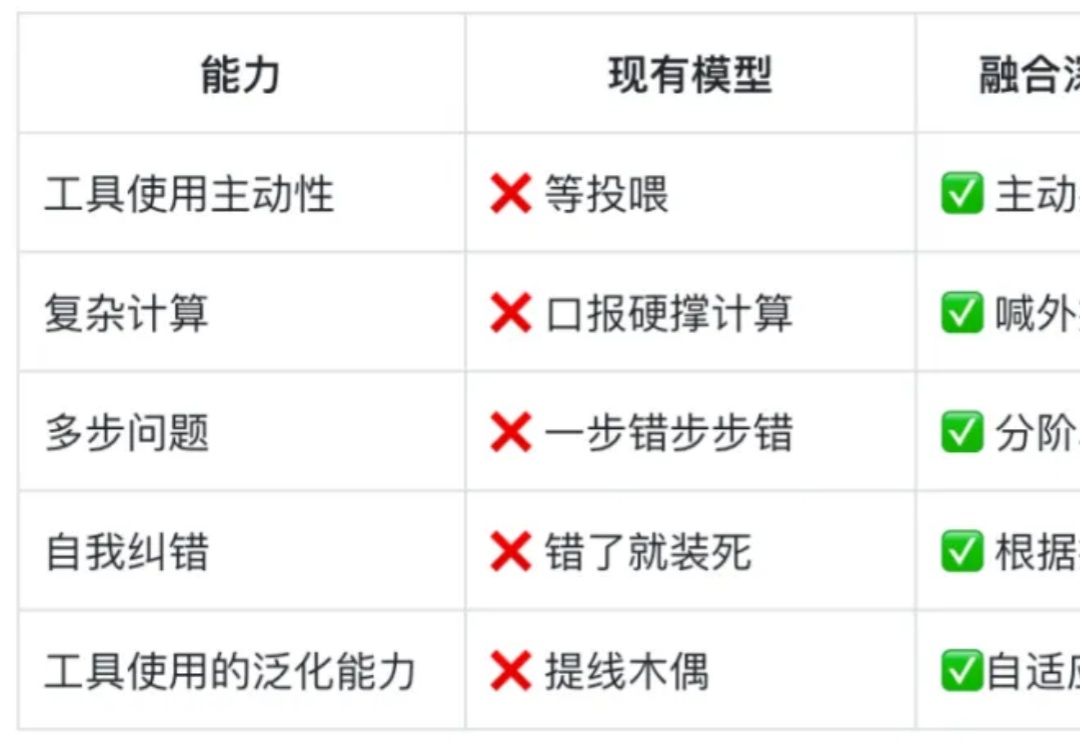
GPT - 4o、Deepseek - R1 等高级模型已展现出令人惊叹的「深度思考」能力:理解上下文关联、拆解多步骤问题、甚至通过思维链(Chain - of - Thought)进行自我验证、自我反思等推理过程。

满血版o3和o4-mini深夜登场,首次将图像推理融入思维链,还会自主调用工具,60秒内破解复杂难题。尤其是,o3以十倍o1算力刷新编程、数学、视觉推理SOTA,接近「天才水平」。此外,OpenAI还开源了编程神器Codex CLI,一夜爆火。

港中文和清华团队推出Video-R1模型,首次将强化学习的R1范式应用于视频推理领域。通过升级的T-GRPO算法和混合图像视频数据集,Video-R1在视频空间推理测试中超越了GPT-4o,展现了强大的推理能力,并且全部代码和数据集均已开源。
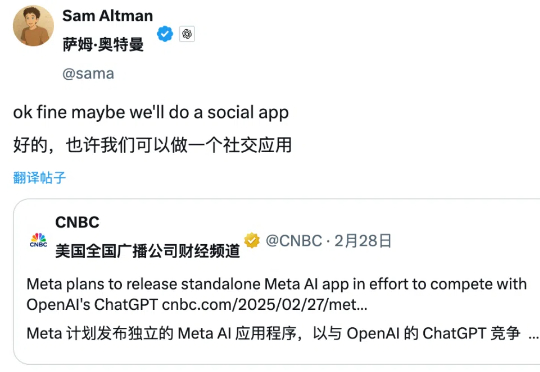
就在刚刚,据外媒 The Verge 援引知情人士消息称,OpenAI 正在研发一个类似 X(前 Twitter)的社交网络。 项目还处于早期阶段,但据称内部已完成原型开发 2️⃣ 项目重点是 ChatGPT 的图像生成功能和社交信息流 3️⃣ CEO Sam Altman 已私下向圈外人征求反馈