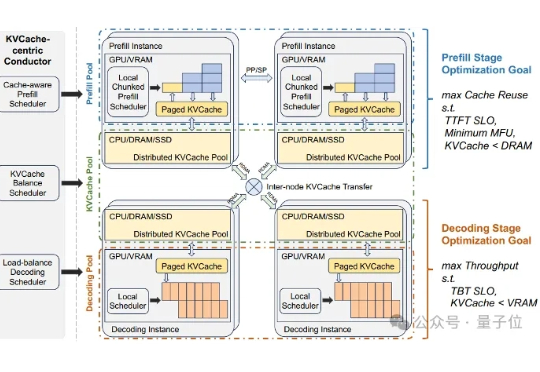
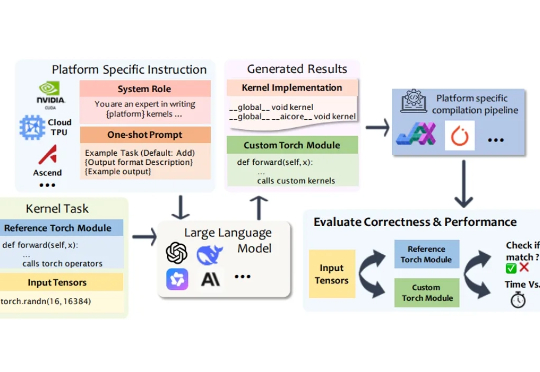
英伟达的局:狂撒15亿美元,从Lambda那租到了搭载自家AI芯片的GPU服务器
英伟达的局:狂撒15亿美元,从Lambda那租到了搭载自家AI芯片的GPU服务器Lambda 收入可观,英伟达主导地位稳固,大家都有美好未来 据 The Information 最新消息称,英伟达已经与小型云服务提供商 Lambda 达成一笔总额高达 15 亿美元的合作协议,内容是前者将租赁后者搭载英伟达自研 AI 芯片的 GPU 服务器。
来自主题: AI资讯
7992 点击 2025-09-07 12:06