
大模型推理学习新范式!ExGRPO框架:从盲目刷题到聪明复盘
大模型推理学习新范式!ExGRPO框架:从盲目刷题到聪明复盘大模型在强化学习过程中,终于知道什么经验更宝贵了! 来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究团队,最近提出了一套经验管理和学习框架ExGRPO—— 通过科学地识别、存储、筛选和学习有价值的经验,让大模型在优化推理能力的道路上,走得更稳、更快、更远。
来自主题: AI技术研报
6727 点击 2025-10-23 15:42
大模型在强化学习过程中,终于知道什么经验更宝贵了! 来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究团队,最近提出了一套经验管理和学习框架ExGRPO—— 通过科学地识别、存储、筛选和学习有价值的经验,让大模型在优化推理能力的道路上,走得更稳、更快、更远。

年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。
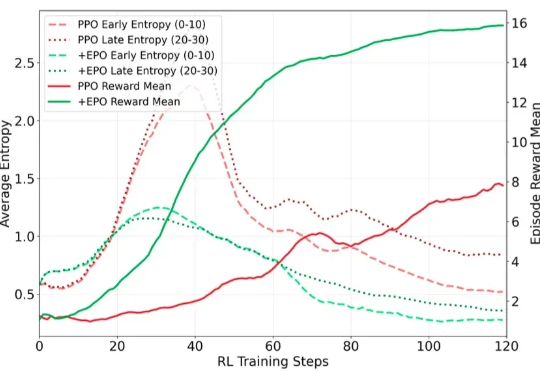
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
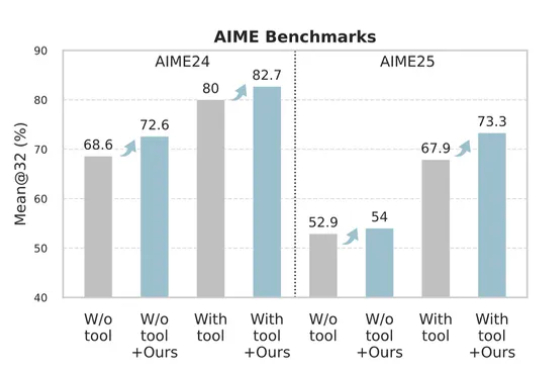
只花120元,效果吊打70000元微调!腾讯提出一种升级大模型智能体的新方法——无训练组相对策略优化Training-Free GRPO。无需调整任何参数,只要在提示词中学习简短经验,即可实现高性价比提升模型性能。
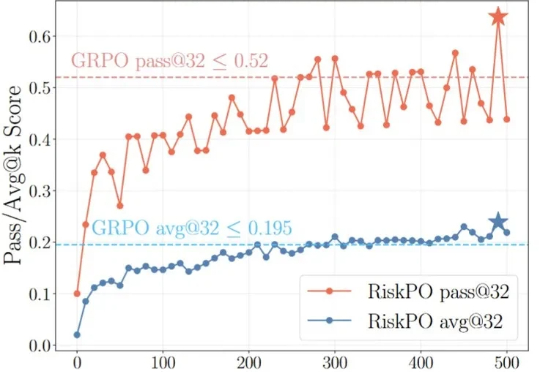
当强化学习(RL)成为大模型后训练的核心工具,「带可验证奖励的强化学习(RLVR)」凭借客观的二元反馈(如解题对错),迅速成为提升推理能力的主流范式。从数学解题到代码生成,RLVR 本应推动模型突破「已知答案采样」的局限,真正掌握深度推理逻辑 —— 但现实是,以 GRPO 为代表的主流方法正陷入「均值优化陷阱」。
对于大模型的强化学习已在数学推理、代码生成等静态任务中展现出不俗实力,而在需要与开放世界交互的智能体任务中,仍面临「两朵乌云」:高昂的 Rollout 预算(成千上万的 Token 与高成本的工具调用)和极其稀疏的「只看结果」的奖励信号。
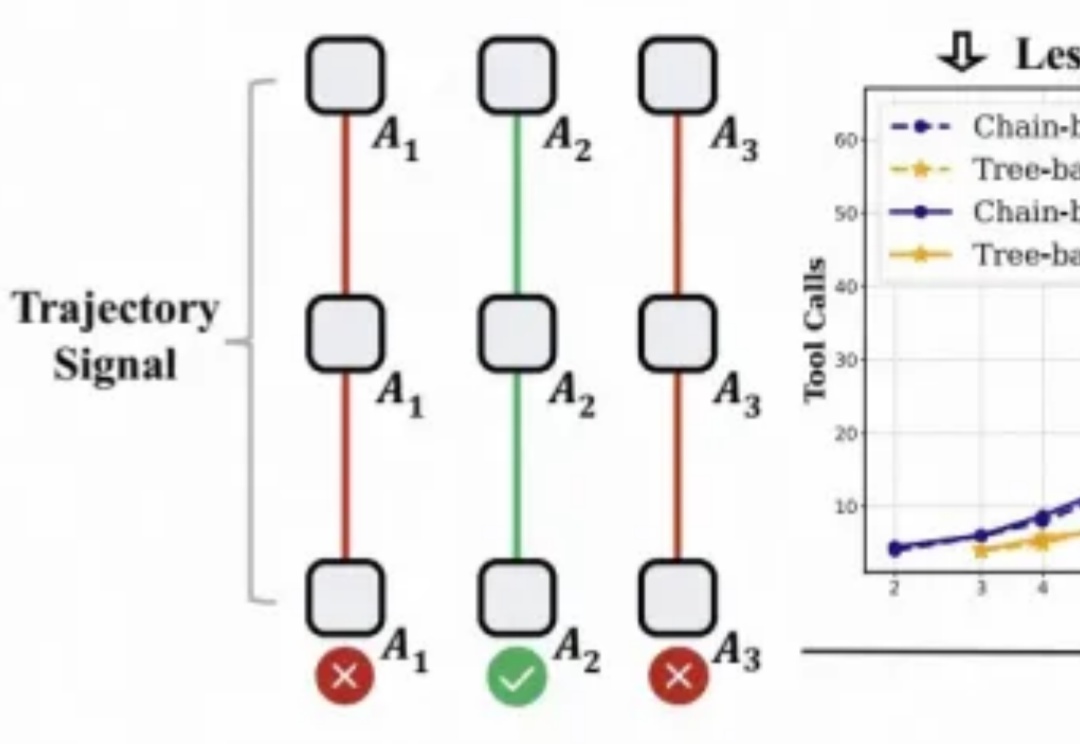
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。

近期,北京大学与字节团队提出了名为 BranchGRPO 的新型树形强化学习方法。不同于顺序展开的 DanceGRPO,BranchGRPO 通过在扩散反演过程中引入分叉(branching)与剪枝(pruning),让多个轨迹共享前缀、在中间步骤分裂,并通过逐层奖励融合实现稠密反馈。
GRPO 就像一个树节点,从这里开始开枝散叶。
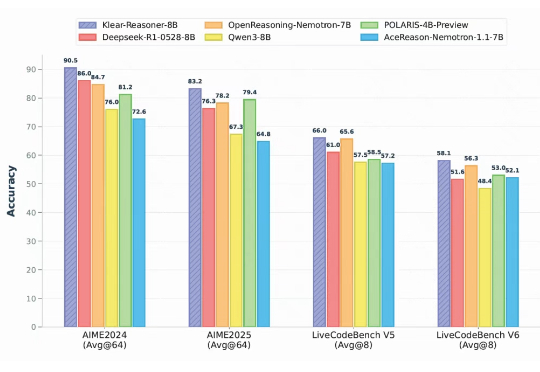
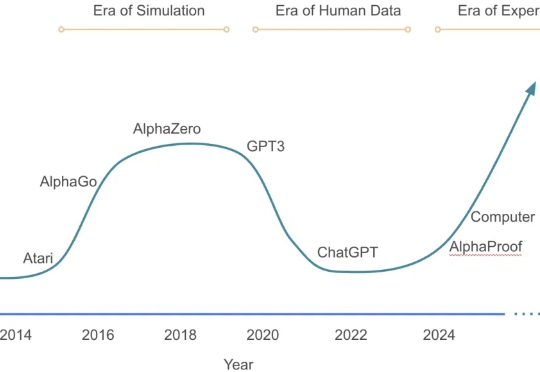
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。