
让视觉语言模型搞空间推理,谷歌又整新活了
让视觉语言模型搞空间推理,谷歌又整新活了视觉语言模型虽然强大,但缺乏空间推理能力,最近 Google 的新论文说它的 SpatialVLM 可以做,看看他们是怎么做的。
来自主题: AI技术研报
9455 点击 2024-02-18 15:10
 搜索
搜索
视觉语言模型虽然强大,但缺乏空间推理能力,最近 Google 的新论文说它的 SpatialVLM 可以做,看看他们是怎么做的。
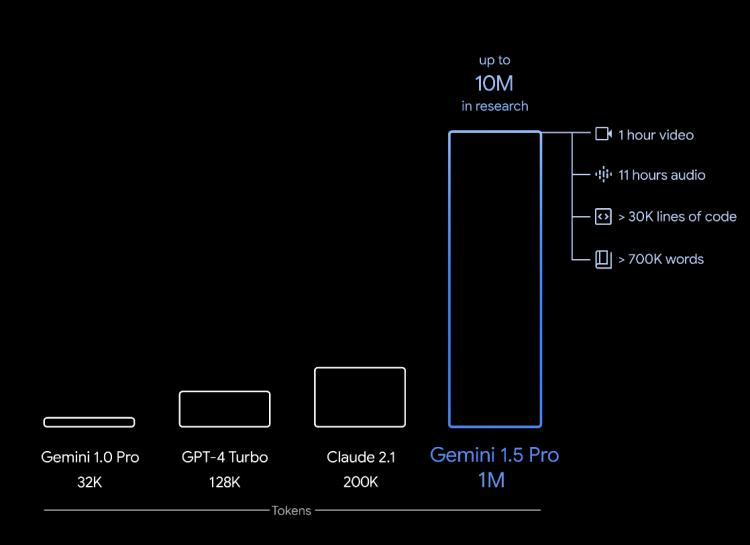
这两天,几乎整个AI圈的目光都被OpenAI发布Sora模型的新闻吸引了去。其实还有件事也值得关注,那就是Google继上周官宣Gemini 1.0 Ultra 后,火速推出下一代人工智能模型Gemini 1.5。
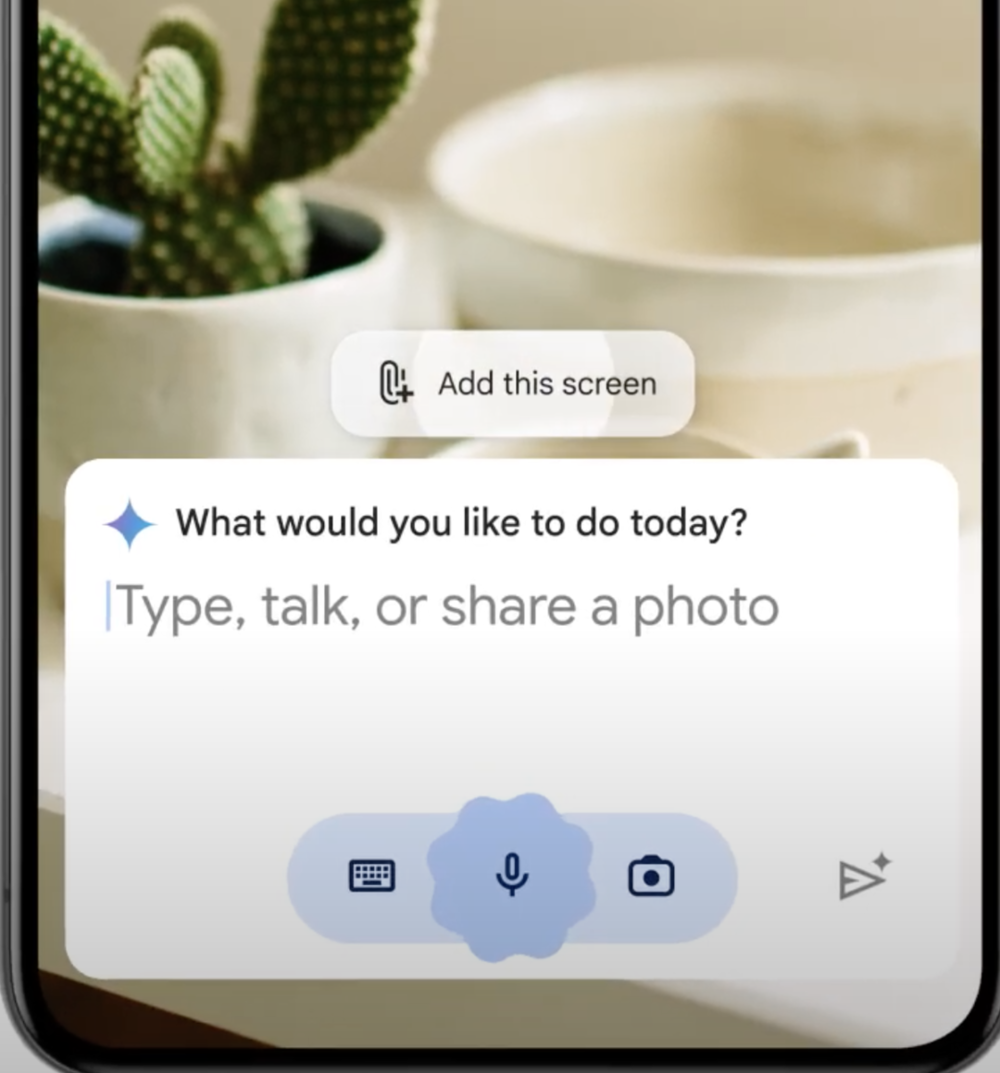
谷歌推出Gemini大规模商业化,将其聊天机器人Bard改名为Gemini,并推出Gemini的Android版App。谷歌还将Gemini的能力加入iOS的Google App中,并免费向公众开放。Gemini还可替代原来的Google Assistant成为手机的默认语言助手。

刚刚,Google推出计划,用户可以每月花 19.99 美金订阅 Google One AI Premium,使用支持 Gemini 的 Gmail、Docs,Sheets,Slides 和 Meet——也就是说,你可以在谷歌办公全家桶中畅享 Gemini 的 AI 功能了。

无论是 Google 翻译、DeepL 翻译还是 ChatGPT,翻译大段英文的时候,“机翻感”(机器翻译的感觉)都很强,一看就是机器翻译的,很生硬,但是自己手动润色又太费时间。

随着技术的不断发展,各种AI模型框架也越来越多,管理和整合多个模型、服务提供商和密钥可能会变得复杂。幸运的是,而今有一款名为“AI 网关”的开源项目可以帮助简化这一过程。

今年初,OpenAI的崛起似乎预示着Google的厄运。但这家科技巨头已经平息了其AI研究人员之间的争吵,并且终于以其最新的AI技术Gemini开始进攻。现在,困难的部分开始了。

2023年底OpenAI推出GPTs上演王炸,Google推出Gemini再次爆破。

这项综述性研究报告批判性地分析了生成式AI的发展现状和发展方向,并探究了谷歌Gemini和备受期待的OpenAI Q*等创新成果将如何改变多个领域的实际应用。
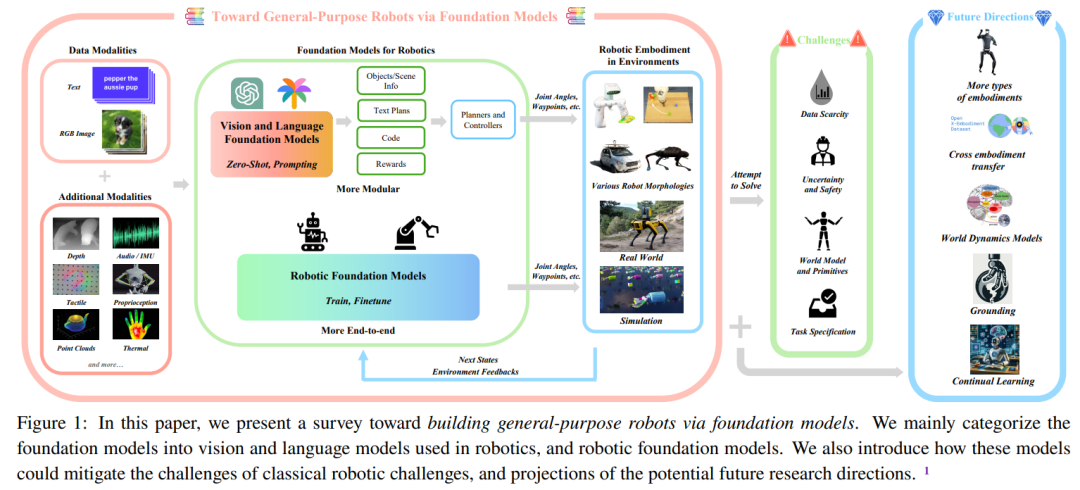
机器人是一种拥有无尽可能性的技术,尤其是当搭配了智能技术时。近段时间创造了许多变革性应用的大模型有望成为机器人的智慧大脑,帮助机器人感知和理解这个世界并制定决策和进行规划。