
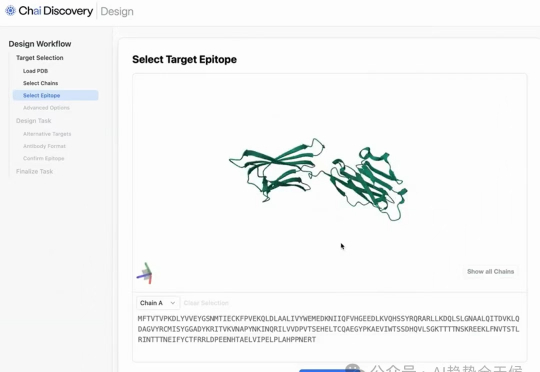
“两周搞定”新药设计?Chai-2: AI驱动抗体设计新突破
“两周搞定”新药设计?Chai-2: AI驱动抗体设计新突破一个叫 Chai-2 的 AI 技术,听说它让制药业的老板们都坐不住了。啥?制药业跟你没关系?别急,故事才刚开始,慢慢聊。
来自主题: AI资讯
8471 点击 2025-07-01 16:31
一个叫 Chai-2 的 AI 技术,听说它让制药业的老板们都坐不住了。啥?制药业跟你没关系?别急,故事才刚开始,慢慢聊。

Fuzozo、Haivivi……取个ABB名字就能爆? 要说2025年最火爆的赛道,潮玩绝对算一个。
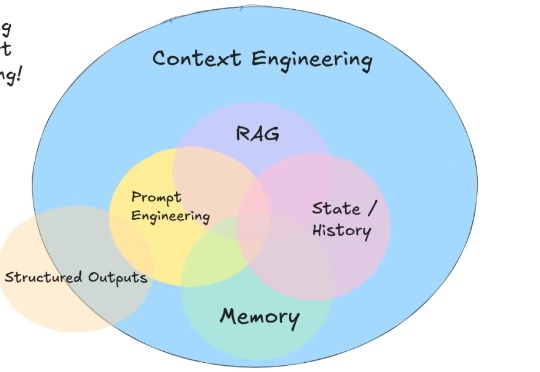
AI 时代,你可能听说过提示词工程、RAG、记忆等术语。但是很少有人提及上下文工程(context engineering)。
本文将介绍 22 种先进的RAG技术,灵感来源于 all-rag-techniques 仓库中的全面实现。这些实现使用 Python 库(如 NumPy、Matplotlib 和 OpenAI 的嵌入模型),避免使用 LangChain 或 FAISS 等依赖,以保持简单性和清晰度。
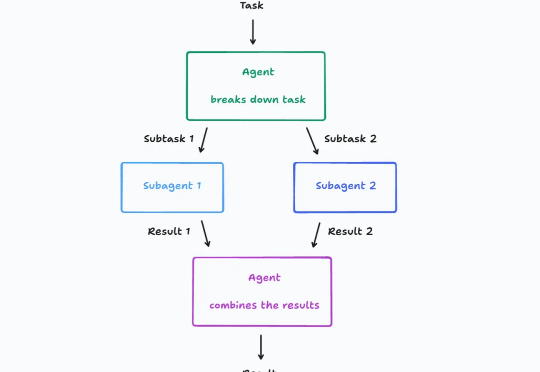
大模型驱动的 AI 智能体(Agent)架构最近讨论的很激烈,其中一个关键争议点在于: 多智能体到底该不该建?

618期间,一款刚推出不到两周的儿童AI硬件登顶了京东婴幼童玩具618累计竞速榜首。同样在榜的,是频繁刷屏的 Haivivi ,以及朱啸虎投的Fuzozo。
前天MiniMax的M1文章里,我说MiniMax得掏一个视频模型出来吧。 于是,果然,前天深夜,他们发了Hailuo 02。
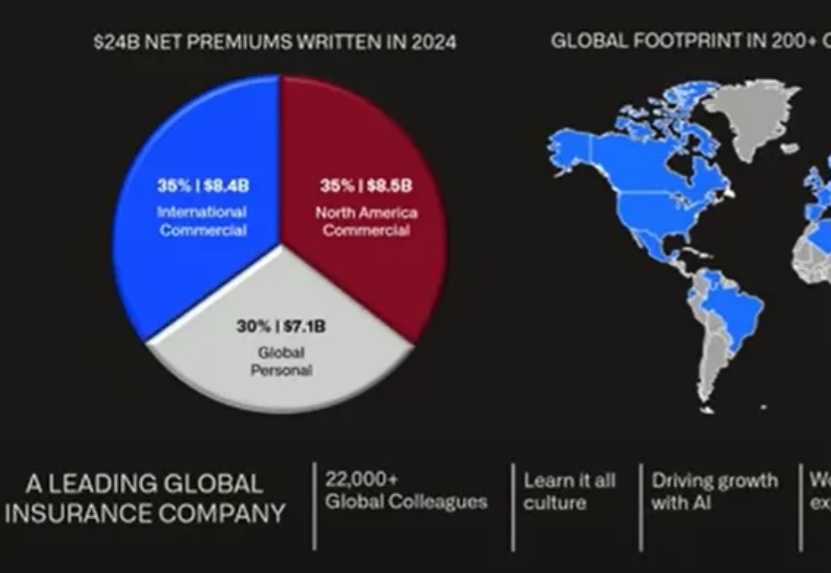
AI应用股王Palantir在6月举办的7thAIP Conference公布了最新一批Agent用例,Palantir公布Agent新用例,不止于next level|AIPCon7介绍了3家医疗客户用例,今天介绍的金融Agent,客户实践出来的企业AI落地原则非常有意义。

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
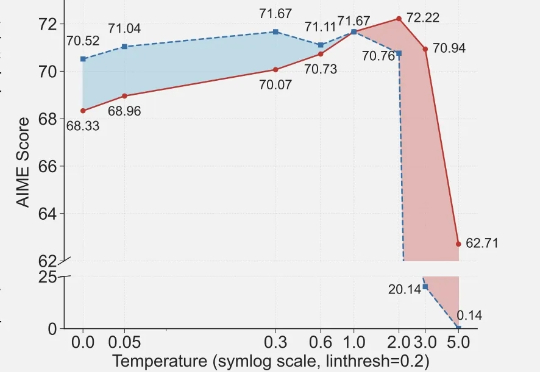
近期arxiv最热门论文,Qwen&清华LeapLab团队最新成果: 在强化学习训练大模型推理能力时,仅仅20%的高熵token就能撑起整个训练效果,甚至比用全部token训练还要好。