
ICLR25|打开RL黑盒,首次证明强化学习存在内在维度瓶颈
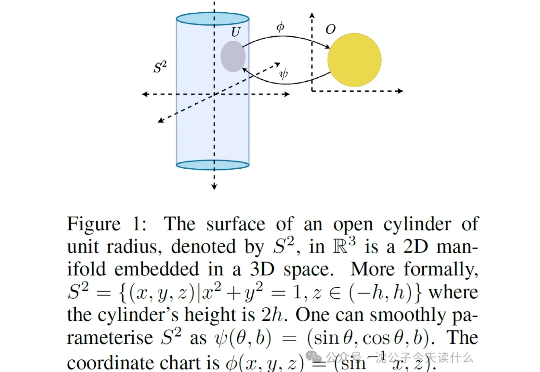
ICLR25|打开RL黑盒,首次证明强化学习存在内在维度瓶颈一句话概括,原来强化学习的“捷径”是天生的,智能体能去的地方(流形)被动作维度(低维流形)限制得死死的,根本没机会去那些没用的高维空间瞎逛。
来自主题: AI资讯
6956 点击 2025-08-05 11:59
一句话概括,原来强化学习的“捷径”是天生的,智能体能去的地方(流形)被动作维度(低维流形)限制得死死的,根本没机会去那些没用的高维空间瞎逛。
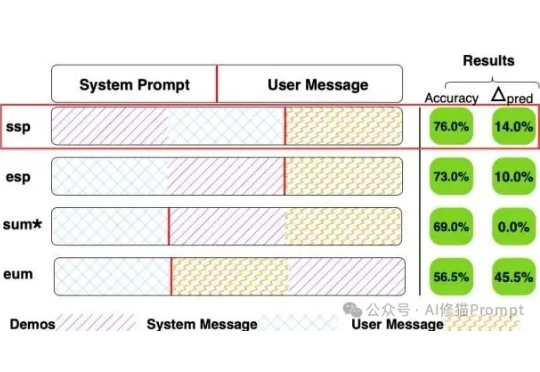
上下文学习(In-Context Learning, ICL)、few-shot,经常看我文章的朋友几乎没有人不知道这些概念,给模型几个例子(Demos),它就能更好地理解我们的意图。但问题来了,当您精心挑选了例子、优化了顺序,结果模型的表现还是像开“盲盒”一样时……有没有可能,问题出在一个我们谁都没太在意的地方,这些例子,到底应该放在Prompt的哪个位置?
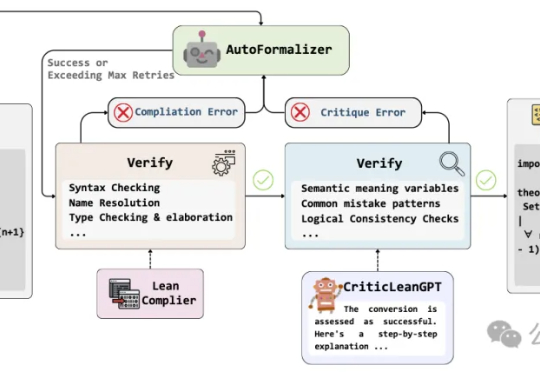
当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。

实时强化学习来了!AI 再也不怕「卡顿」。 设想这样一个未来场景:多个厨师机器人正在协作制作煎蛋卷。
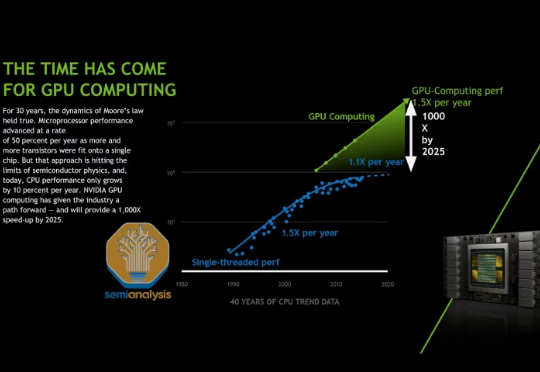
在我们去年 AI Scaling Laws article from late last year中,我们探讨了多层 AI 扩展定律如何持续推动 AI 行业向前发展,使得模型能力的增长速度超过了摩尔定律,并且单位 token 成本也相应地迅速降低。
在今年 ICLR 会议上,我们被问到最多且最有意思的问题是:像 Jina AI 这样的向量搜索模型提供商,除了在 MTEB 上做基准测试,会不会做些氛围测试 (Vibe-testing)?

上月,ChatGPT-4o无条件跪舔用户,被OpenAI紧急修复。然而,ICLR 2025的文章揭示LLM不止会「跪舔」,还有另外5种「套路」。
当您的Agent需要规划多步骤操作以达成目标时,比如游戏策略制定或旅行安排优化等等,传统规划方法往往需要复杂的搜索算法和多轮提示,计算成本高昂且效率不佳。来自Google DeepMind和CMU的研究者提出了一个简单却非常烧脑的问题:我们是否一直在用错误的方式选择示例来引导LLM学习规划?

扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。
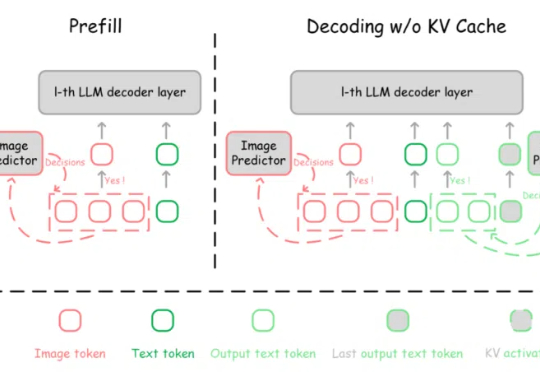
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。