ICLR高分论文险遭拒,只因未引用「造假」研究???作者怒喷:对方论文用Claude生成
ICLR高分论文险遭拒,只因未引用「造假」研究???作者怒喷:对方论文用Claude生成有在离谱。 高分论文因为没有引用先前的研究而被ICLR拒稿了?!
来自主题: AI资讯
7746 点击 2025-04-14 15:24
 搜索
搜索
有在离谱。 高分论文因为没有引用先前的研究而被ICLR拒稿了?!

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。

大家还记得那个 ICLR 2025 首次满分接收、彻底颠覆静态图像光照编辑的工作 IC-Light 吗?
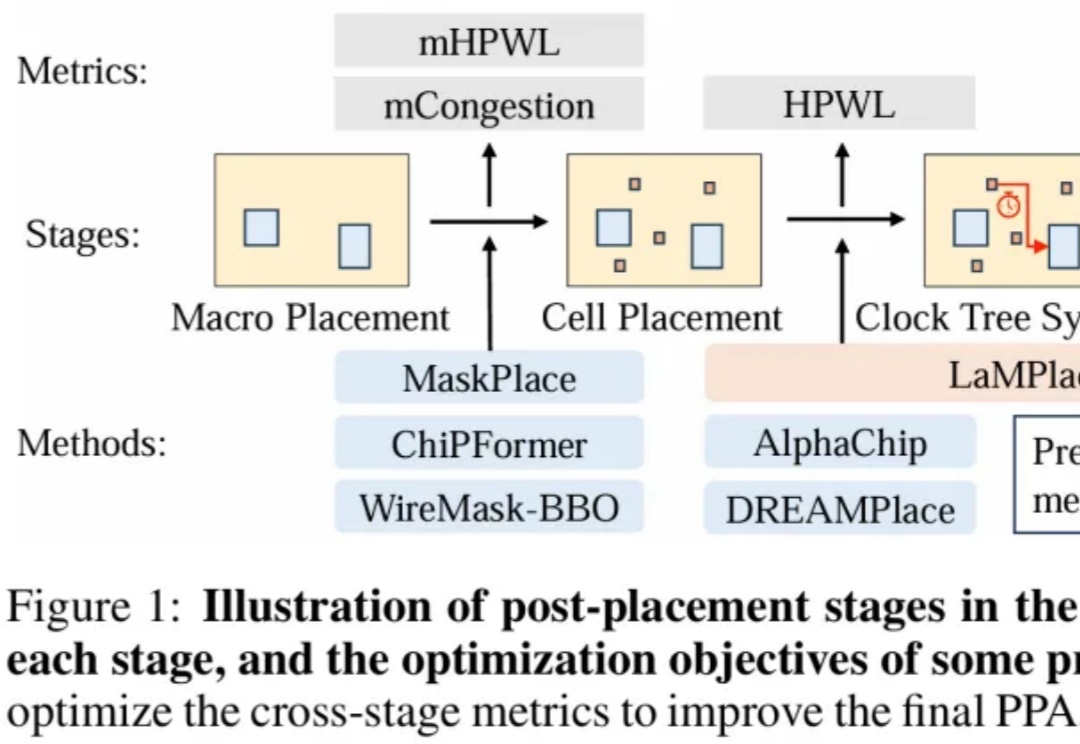
用AI指导芯片设计,中科大王杰教授团队、华为诺亚实验室、天津大学提出全新芯片宏单元布局优化方法LaMPlace!
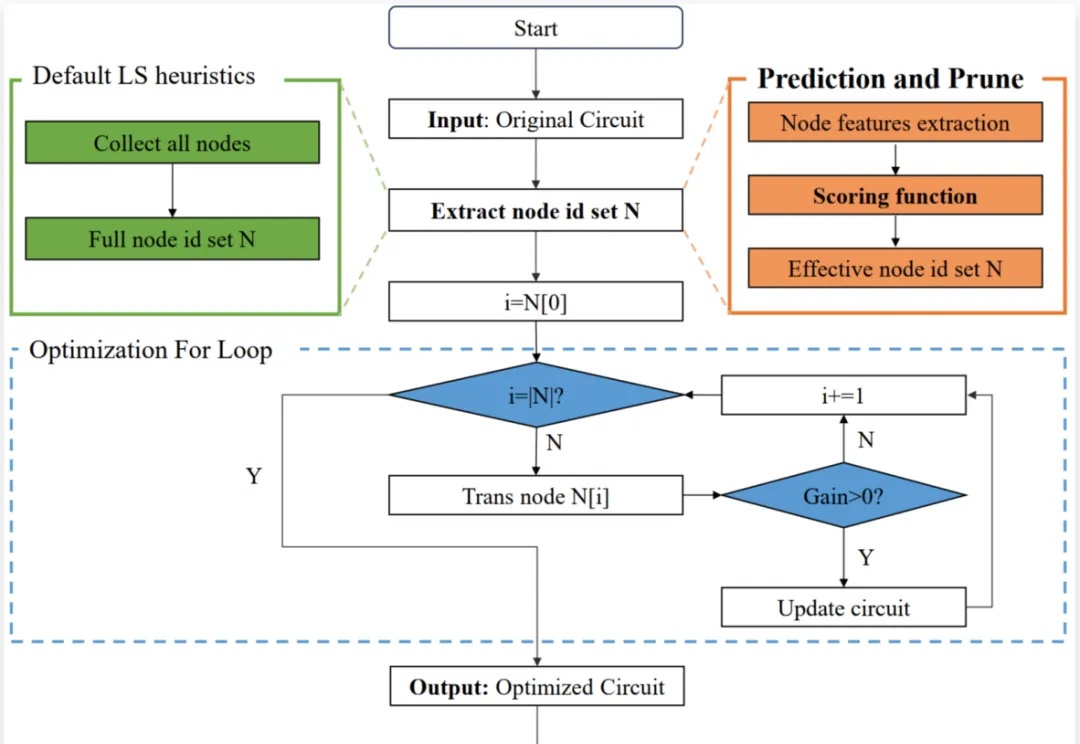
芯片设计是现代科技的核心,逻辑优化(Logic Optimization, LO)作为芯片设计流程中的关键环节,其效率直接影响着芯片设计的整体性能。
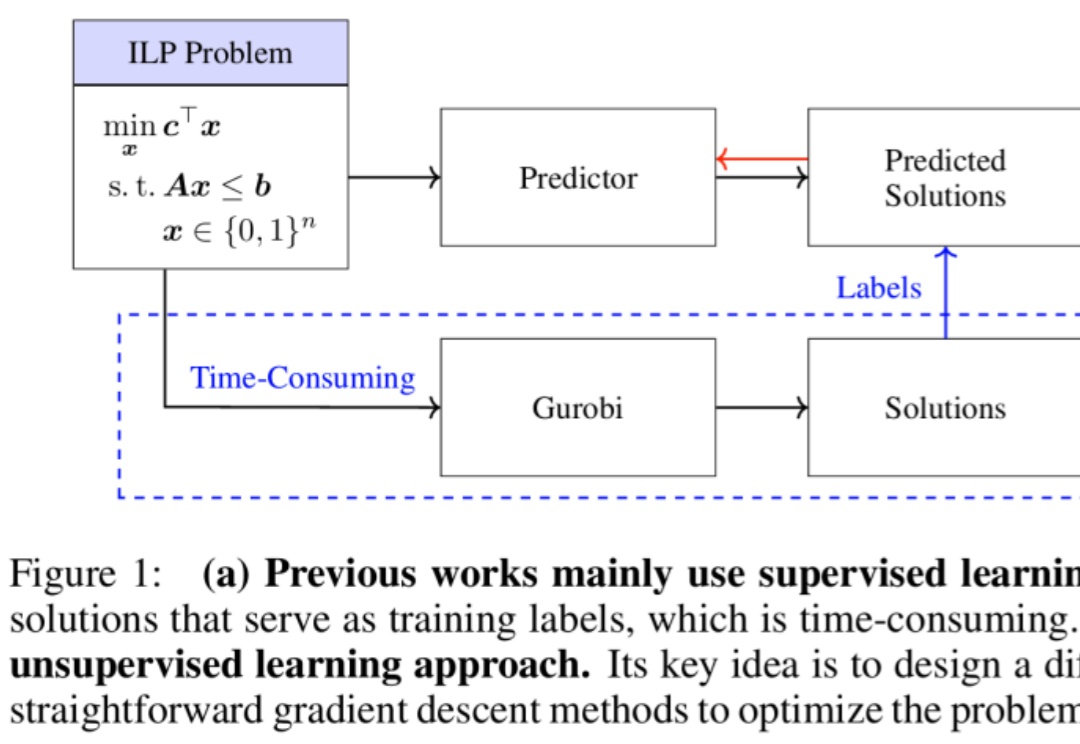
无监督学习训练整数规划求解器的新范式来了。

嚯!完全由AI生成的论文,通过顶会ICLR workshop评审?!

让大语言模型更懂特定领域知识,有新招了!

低秩适配器(LoRA)能够在有监督微调中以约 5% 的可训练参数实现全参数微调 90% 性能。
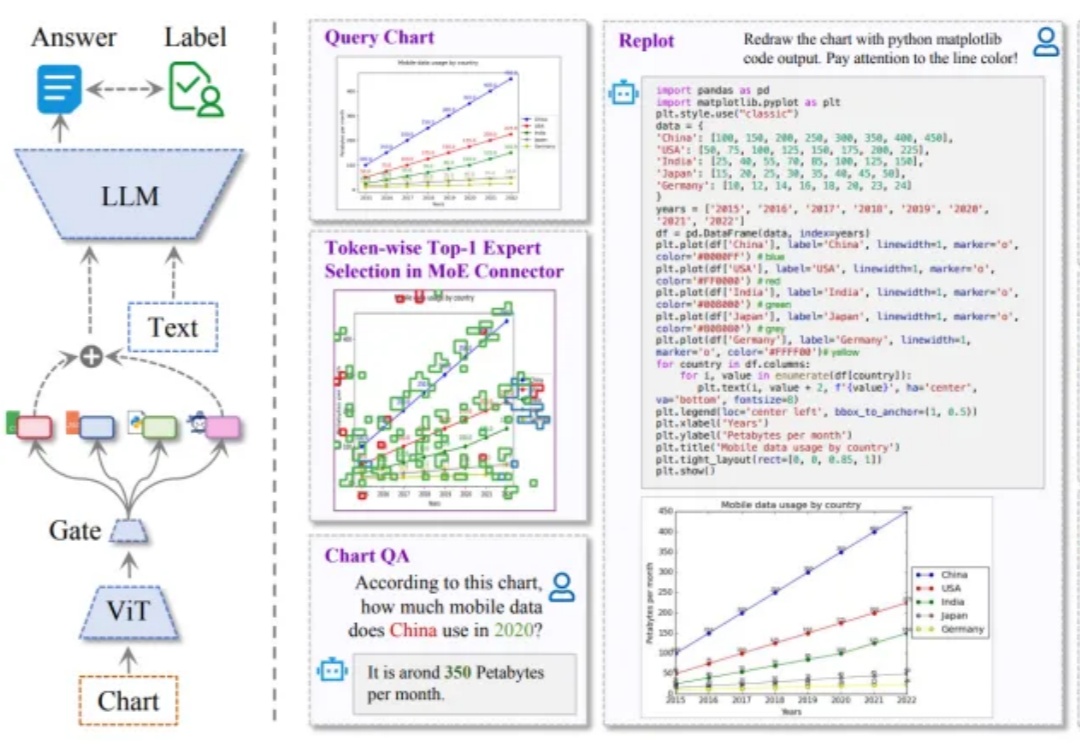
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由 IDEA、清华大学、北京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文。据了解,本届大会共收到 11672 篇论文,被选中做 Oral Presentation(口头报告)的比例约为 1.8%