

字节TikTok算法负责人陈志杰或于近期离职,已开启AI Coding方向创业
字节TikTok算法负责人陈志杰或于近期离职,已开启AI Coding方向创业蓝鲸新闻从多位知情人士处获悉,字节跳动TikTok算法负责人陈志杰或于近期离职,目前,他已经开启AI领域创业,知情人士称,陈志杰创业的方向为AI Coding方向,目前已经在陆续接触投资人。
来自主题: AI资讯
7902 点击 2024-12-25 13:52
蓝鲸新闻从多位知情人士处获悉,字节跳动TikTok算法负责人陈志杰或于近期离职,目前,他已经开启AI领域创业,知情人士称,陈志杰创业的方向为AI Coding方向,目前已经在陆续接触投资人。

未来,抖音神曲可能都会被AI猫猫唱一遍。

HeyGen是一个帮助人们创建、本地化和个性化视频的AI平台。解决问题的关键在于提升AI的质量,让视频与实际内容更加匹配、更加引人入胜、更能传递信息。
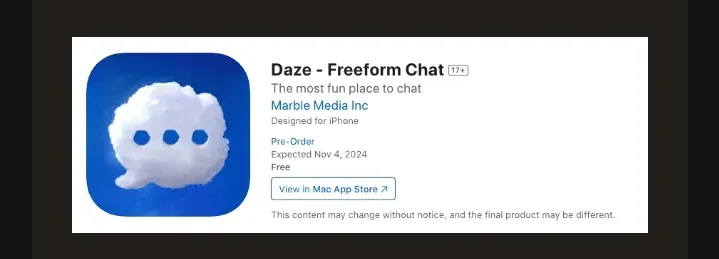
在 TikTok 上,Daze 最受欢迎的视频已被观看了 800 万次。在TikTok和Instagram上,旨在针对 Z 世代的新消息应用背后的初创公司已获得约 4800 万的总观看次数。

随着大规模语言模型的快速发展,如 GPT、Claude 等,LLM 通过预训练海量的文本数据展现了惊人的语言生成能力。然而,即便如此,LLM 仍然存在生成不当或偏离预期的结果。这种现象在推理过程中尤为突出,常常导致不准确、不符合语境或不合伦理的回答。为了解决这一问题,学术界和工业界提出了一系列对齐(Alignment)技术,旨在优化模型的输出,使其更加符合人类的价值观和期望。

情感陪伴类 AI 能否诞生出下一个 TikTok? 最近,乙女游戏的热度持续攀升。前有上线八个月就在全球吸金超 2 亿美元的新晋乙女游戏 Top《恋与深空》,后有乙游玩家与说唱歌手互怼风波,这也让大众注意到了类虚拟恋爱产品的火爆及背后的巨大市场。

中国AI出海,想造出下一个TikTok

硅谷科技巨头的财报陆续发布,有的股票涨了,有的跌了。 不过不重要,我们关注的是,这些在 AI 上投入了巨资的巨头们,到底,谁在 AI 上挣到钱了?
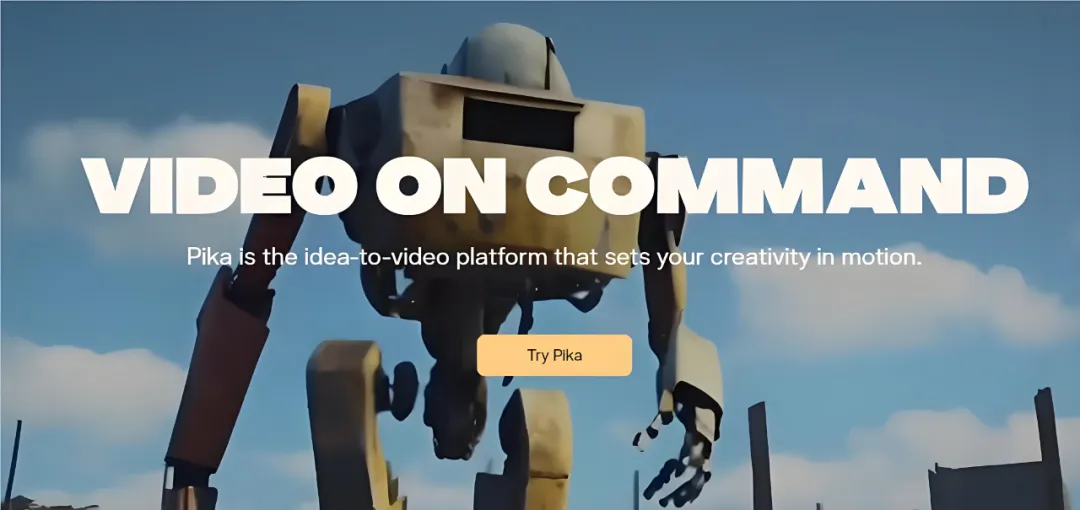
6月5日,AI 视频生成工具 Pika 宣布了它新近完成的 8000万美元 B 轮融资。
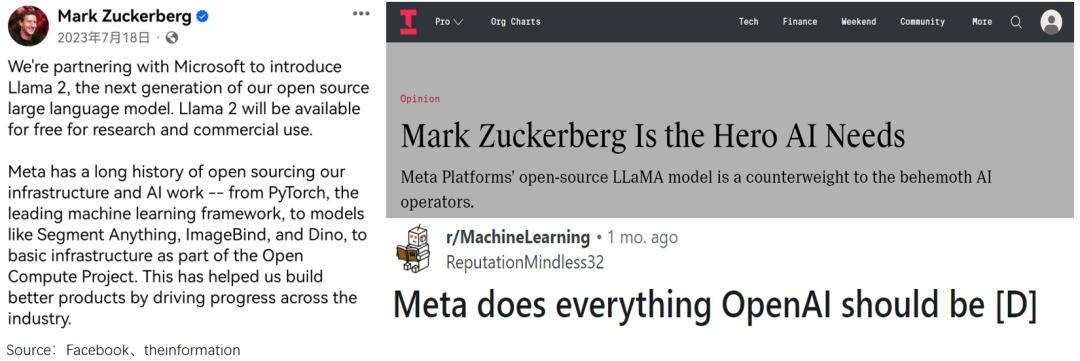
2023年5月,美国白宫举办了一场AI主题闭门会,嘉宾名单汇聚了中青少三代——老资历谷歌、微软,新星OpenAI,初创的Anthropic,却唯独没有Meta。