
Llama系列上新多模态!3.2版本开源超闭源,还和Arm联手搞了手机优化版
Llama系列上新多模态!3.2版本开源超闭源,还和Arm联手搞了手机优化版在多模态领域,开源模型也超闭源了!
来自主题: AI资讯
7769 点击 2024-09-27 11:51
 搜索
搜索
在多模态领域,开源模型也超闭源了!
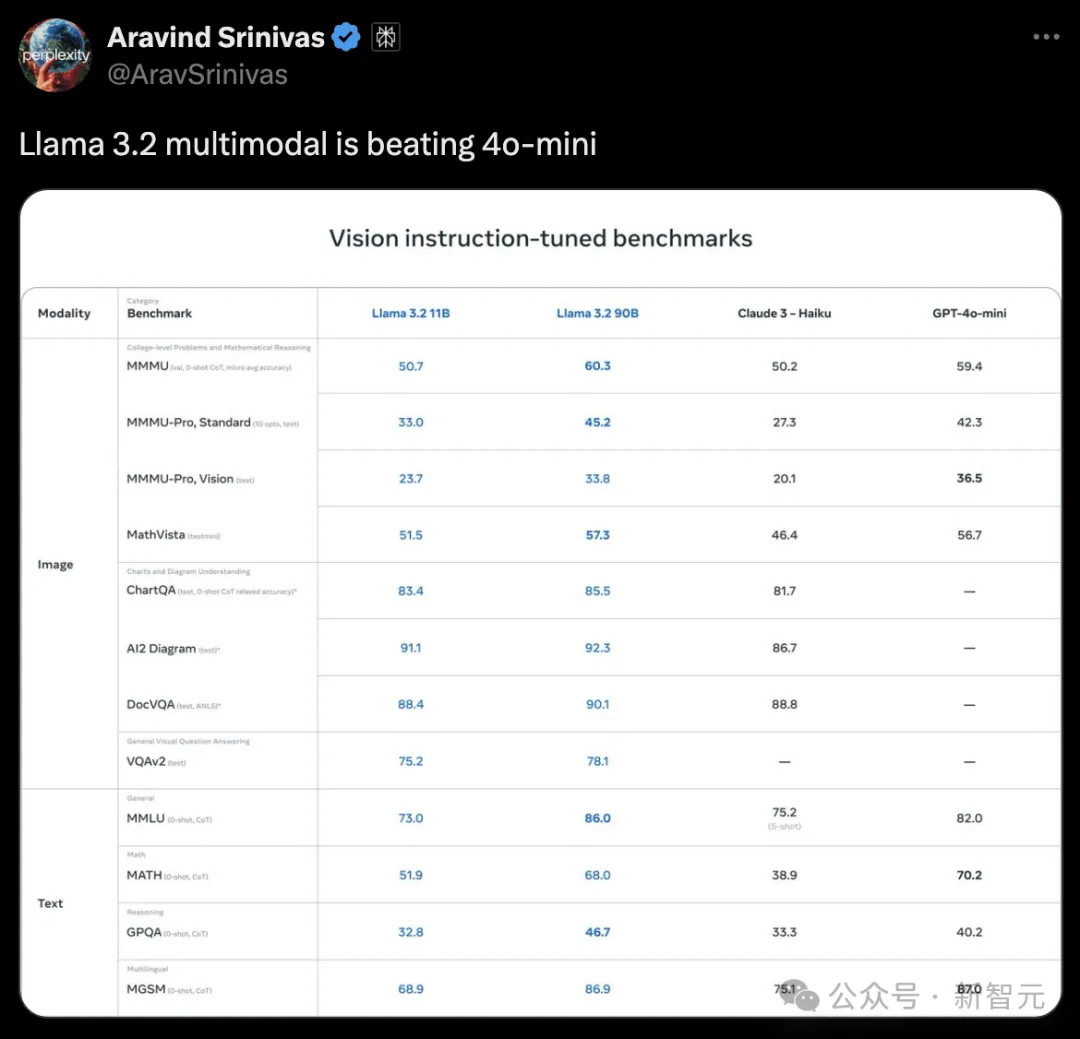
Meta首个理解图文的多模态Llama 3.2来了!这次,除了11B和90B两个基础版本,Meta还推出了仅有1B和3B轻量级版本,适配了Arm处理器,手机、AR眼镜边缘设备皆可用。

就在刚刚,小扎携掉最强AR眼镜Orion登场!Meta首款AR眼镜,苦研十年后,终于诞生了,成本高达10000美元。果然,小扎让我们离元宇宙又近了一步。这会是一次全新的范式转变吗?

Meta Connect 2024推出Quest 3S、Llama 3.2与AR眼镜Orion。
“可以肯定,明天对于AI开发者而言是个大日子。”

LLaMA-Omni能够接收语音指令,同步生成文本和语音响应,响应延迟低至 226ms,低于 GPT-4o 的平均音频响应延迟 320ms。

视觉 / 激光雷达里程计是计算机视觉和机器人学领域中的一项基本任务,用于估计两幅连续图像或点云之间的相对位姿变换。它被广泛应用于自动驾驶、SLAM、控制导航等领域。最近,多模态里程计越来越受到关注,因为它可以利用不同模态的互补信息,并对非对称传感器退化具有很强的鲁棒性。
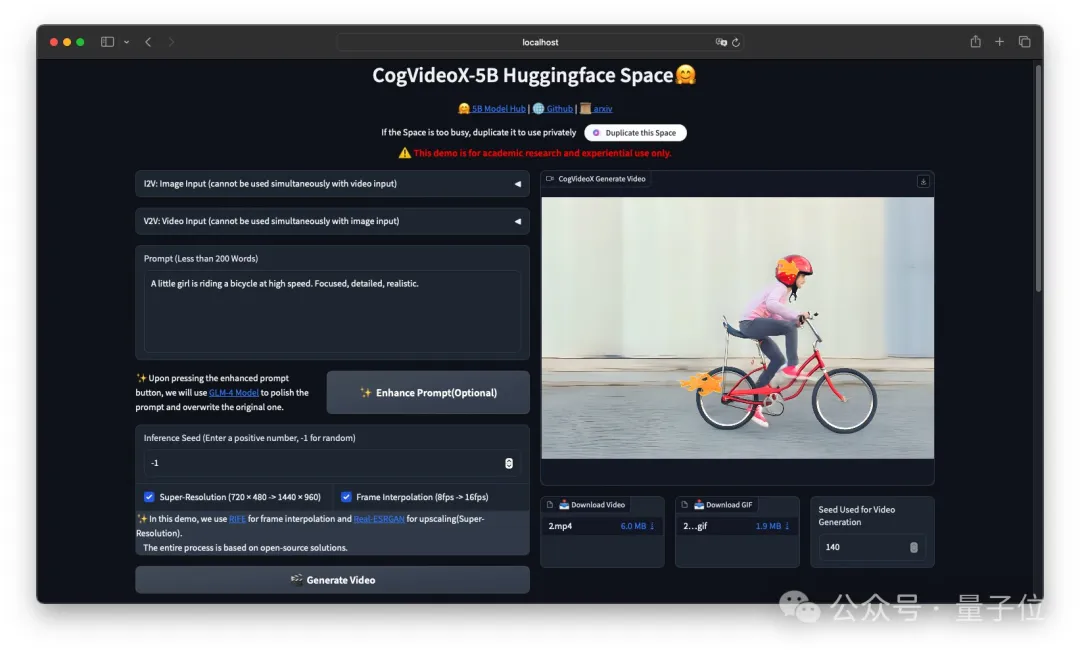
刚刚,智谱把清影背后的图生视频模型CogVideoX-5B-I2V给开源了!(在线可玩) 一起开源的还有它的标注模型cogvlm2-llama3-caption。
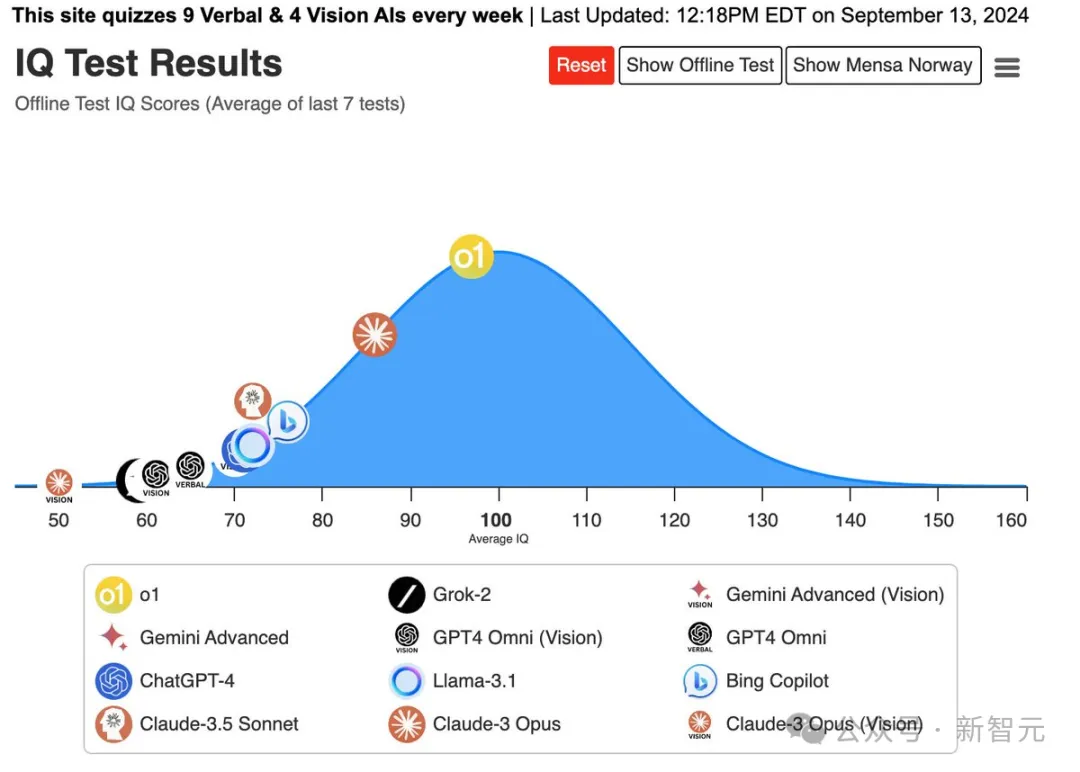
OpenAI o1,在IQ测试中拿到了第一名!大佬Maxim Lott,给o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等进行了智商测试,结果表明,o1稳居第一名。

把Llama 3蒸馏到Mamba,推理速度最高可提升1.6倍!