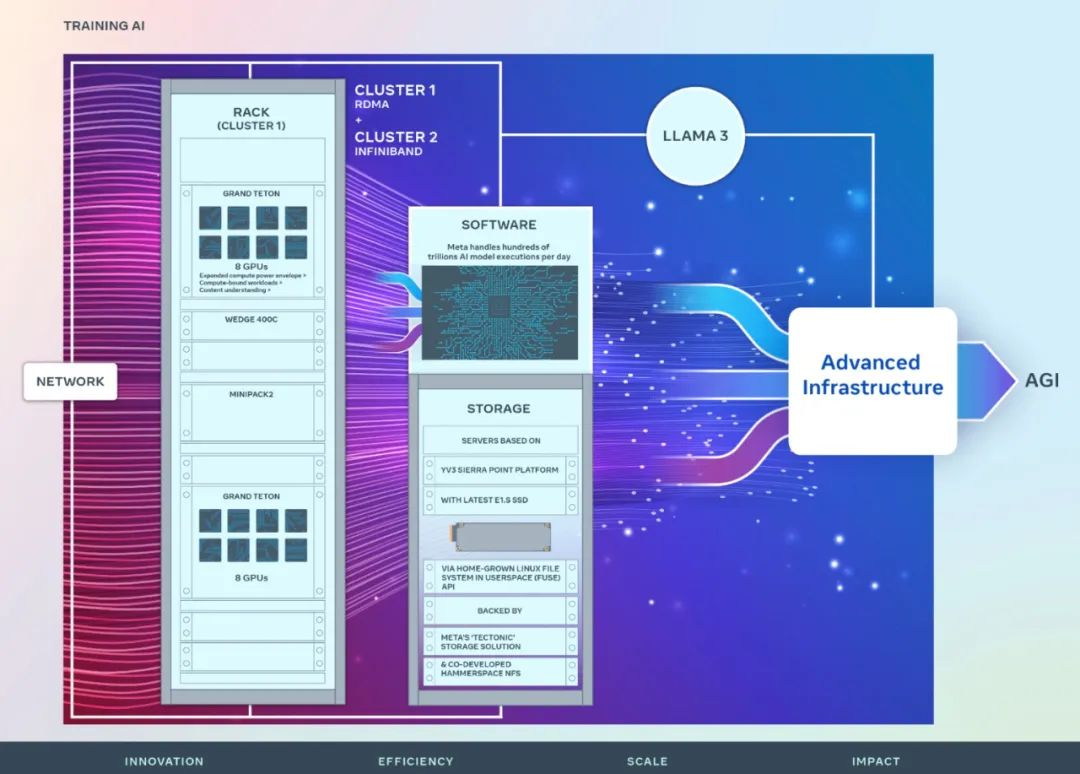
专为训练Llama 3,Meta 4.9万张H100集群细节公布
专为训练Llama 3,Meta 4.9万张H100集群细节公布刚刚,Meta 宣布推出两个 24k GPU 集群(共 49152 个 H100),标志着 Meta 为人工智能的未来做出了一笔重大的投资。
来自主题: AI资讯
10558 点击 2024-03-13 14:42
 搜索
搜索
刚刚,Meta 宣布推出两个 24k GPU 集群(共 49152 个 H100),标志着 Meta 为人工智能的未来做出了一笔重大的投资。

半年多来,Meta 开源的 LLaMA 架构在 LLM 中经受了考验并大获成功(训练稳定、容易做 scaling)。

参照SuperCLUE(中文通用大模型综合性测评基准)框架专门定制了1000道题目集,一一测试了ChatGPT4、 智谱chatGLM-4、Baichuan2-Turbo、百度ERNIE-Bot 4.0、Yi-34B-chat、llama 2等模型在保险业务上的表现。

线性RNN赢了?近日,谷歌DeepMind一口气推出两大新架构,在d基准测试中超越了Transformer。新架构不仅保证了高效的训练和推理速度,并且成功扩展到了14B。
如果说 OpenAI 已经占据了今天闭源大模型生态的一极,那 Meta 无疑是代表开源大模型的另一极。

Google 最近在大模型上动作不断,先是发布了性能更强大的多模态 Gemini 1.5 Pro,然后是开源的小模型 Gemma,评测结果超过了 7b 量级的 Llama 2。

2023 年我们正见证着多模态大模型的跨越式发展,多模态大语言模型(MLLM)已经在文本、代码、图像、视频等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。以 Llama 2,Mixtral 为代表的大语言模型(LLM),以 GPT-4、Gemini、LLaVA 为代表的多模态大语言模型跨越式发展。

LLaMa 3 正寻找安全与可用性的新平衡点。
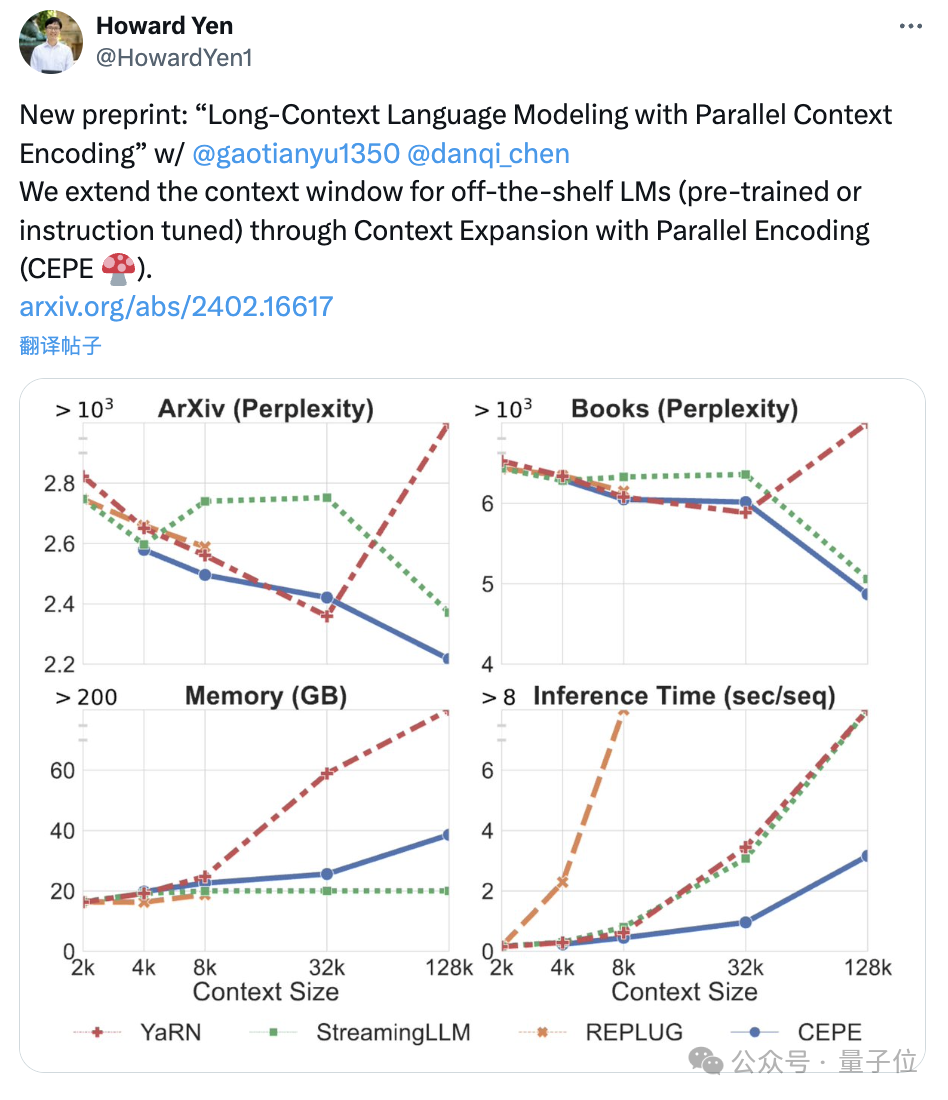
陈丹琦团队刚刚发布了一种新的LLM上下文窗口扩展方法:它仅用8k大小的token文档进行训练,就能将Llama-2窗口扩展至128k。
这两天,Groq惊艳亮相。它以号称“性价比高英伟达100倍”的芯片,实现每秒500tokens大模型生成,感受不到任何延迟。外加谷歌TPU团队这样一个高精尖人才Buff,让不少人直呼:英伟达要被碾压了……