
7B小模型超越DeepSeek-R1:模仿人类教师,弱模型也能教出强推理LLM | Transformer作者团队
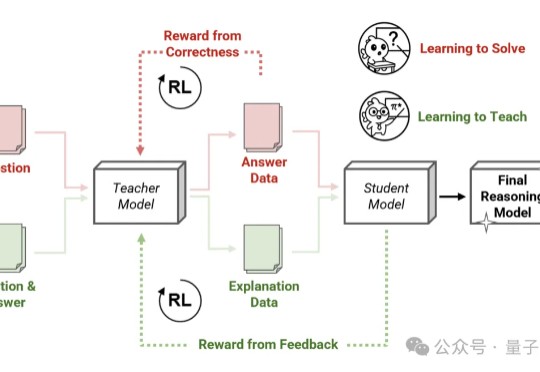
7B小模型超越DeepSeek-R1:模仿人类教师,弱模型也能教出强推理LLM | Transformer作者团队Thinking模式当道,教师模型也该学会“启发式”教学了—— 由Transformer作者之一Llion Jones创立的明星AI公司Sakana AI,带着他们的新方法来了!
来自主题: AI技术研报
8320 点击 2025-06-25 10:55
Thinking模式当道,教师模型也该学会“启发式”教学了—— 由Transformer作者之一Llion Jones创立的明星AI公司Sakana AI,带着他们的新方法来了!
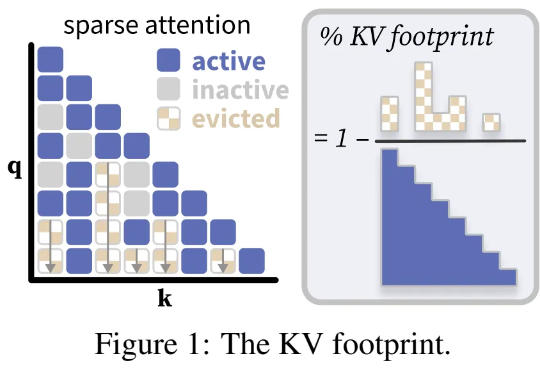
普林斯顿大学计算机科学系助理教授陈丹琦团队又有了新论文了。近期,诸如「长思维链」等技术的兴起,带来了需要模型生成数万个 token 的全新工作负载。
人类从农耕时代到工业时代花了数千年,从工业时代到信息时代又花了两百多年,而 LLM 仅出现不到十年,就已将曾经遥不可及的人工智能能力普及给大众,让全球数亿人能够通过自然语言进行创作、编程和推理。
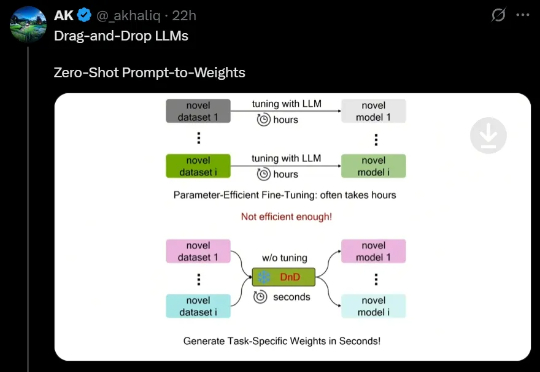
最近,来自NUS、UT Austin等机构的研究人员创新性地提出了一种「拖拽式大语言模型」(DnD),它可以基于提示词快速生成模型参数,无需微调就能适应任务。不仅效率最高提升12000倍,而且具备出色的零样本泛化能力。

现有的语言大模型(LLMs)在复杂指令下的理解和执行能力仍需提升。
大语言模型(LLM)能力提升引发对潜在风险的担忧,洞察其内部“思维过程”、识别危险信号成AI安全核心挑战。
强化学习可以提升LLM推理吗?英伟达ProRL用超2000步训练配方给出了响亮的答案。仅15亿参数模型,媲美Deepseek-R1-7B,数学、代码等全面泛化。
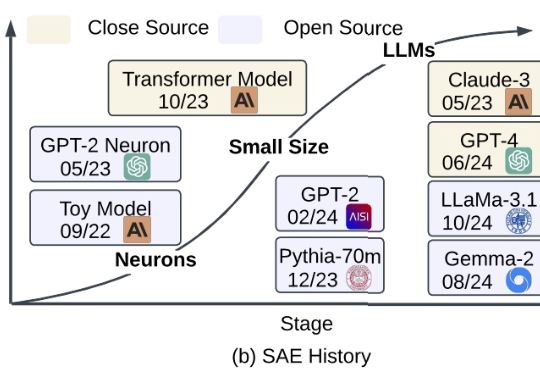
在 ChatGPT 等大语言模型(LLMs)席卷全球的今天,越来越多的研究者意识到:我们需要的不只是 “会说话” 的 LLM,更是 “能解释” 的 LLM。
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。
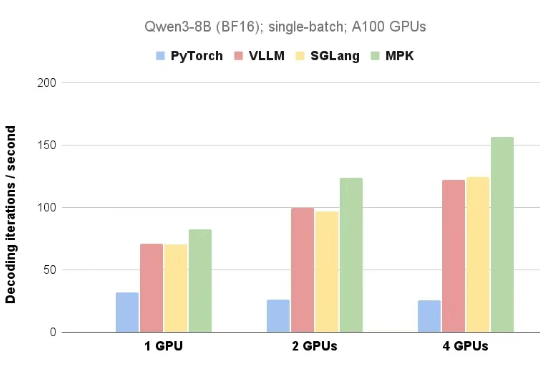
在 AI 领域,英伟达开发的 CUDA 是驱动大语言模型(LLM)训练和推理的核心计算引擎。