
微软副总裁X上「开课」,连更关于RL的一切,LLM从业者必读
微软副总裁X上「开课」,连更关于RL的一切,LLM从业者必读别人都在用 X 发帖子,分享新鲜事物,微软副总裁 Nando de Freitas 却有自己的想法:他要在 X 上「开课」,发布一些关于人工智能教育的帖子。该系列会从 LLM 的强化学习开始,然后逐步讲解扩散、流匹配,以及看看这些技术接下来会如何发展。
来自主题: AI资讯
8038 点击 2025-05-26 17:18
别人都在用 X 发帖子,分享新鲜事物,微软副总裁 Nando de Freitas 却有自己的想法:他要在 X 上「开课」,发布一些关于人工智能教育的帖子。该系列会从 LLM 的强化学习开始,然后逐步讲解扩散、流匹配,以及看看这些技术接下来会如何发展。
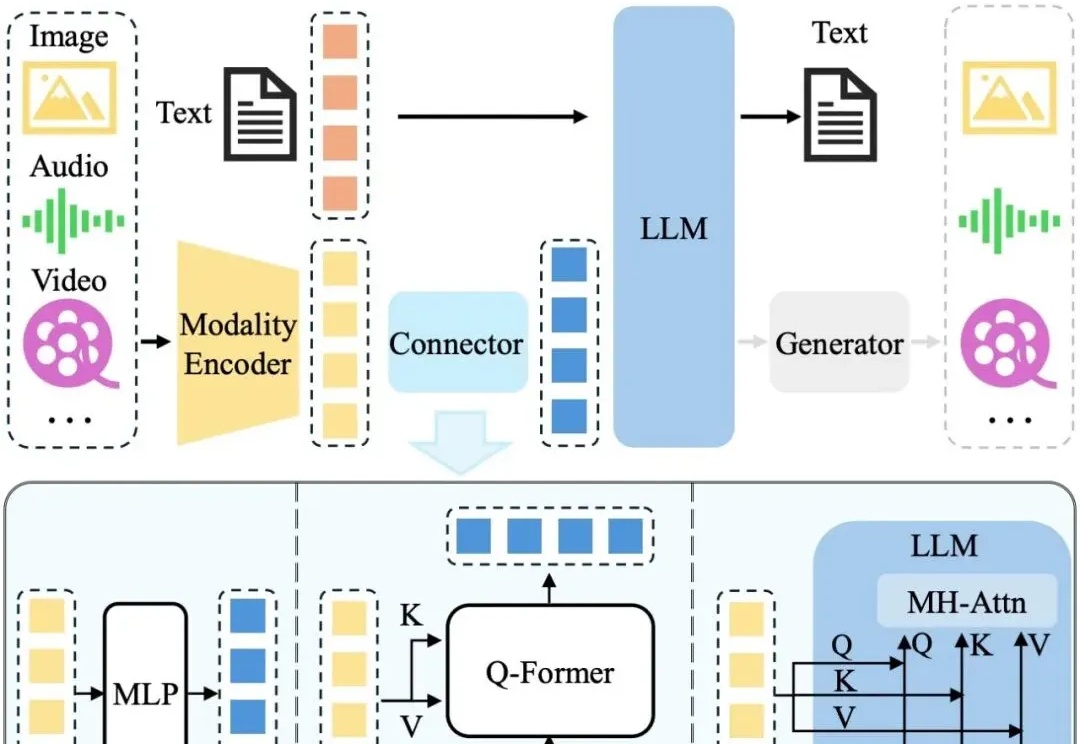
近年来,LLM 及其多模态扩展(MLLM)在多种任务上的推理能力不断提升。然而, 现有 MLLM 主要依赖文本作为表达和构建推理过程的媒介,即便是在处理视觉信息时也是如此 。
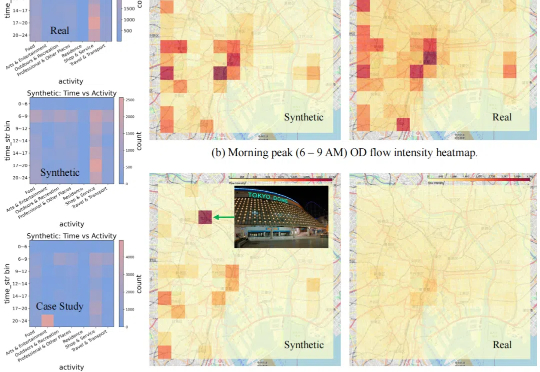
现有的数据合成方法在合理性和分布一致性方面存在不足,且缺乏自动适配不同数据的能力,扩展性较差。

在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:

上月,ChatGPT-4o无条件跪舔用户,被OpenAI紧急修复。然而,ICLR 2025的文章揭示LLM不止会「跪舔」,还有另外5种「套路」。
大家好,我是袋鼠帝 一直以来,分享了不少关于工作流平台、LLM应用平台的不少干货文章。 主要包含:Dify、Coze、n8n、Fastgpt、Ragflow。大家好,我是袋鼠帝 一直以来,分享了不少关于工作流平台、LLM应用平台的不少干货文章。 主要包含:Dify、Coze、n8n、Fastgpt、Ragflow
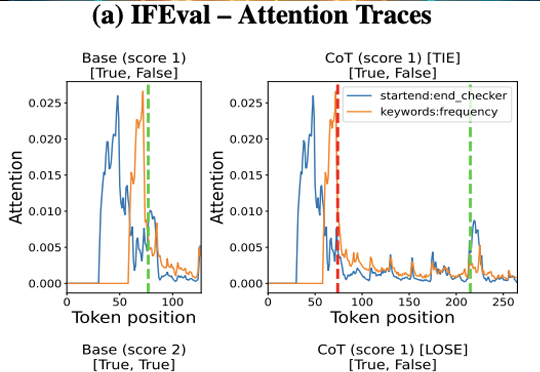
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了!

大语言模型(LLM)的生成范式正在从传统的「单人书写」向「分身协作」转变。传统自回归解码按顺序生成内容,而新兴的异步生成范式通过识别语义独立的内容块,实现并行生成。

洛桑联邦理工学院研究团队发现,当GPT-4基于对手个性化信息调整论点时,64%的情况下说服力超过人类。实验通过900人参与辩论对比人机表现,结果显示个性化AI达成一致概率提升81.2%。研究警示LLM可能被用于传播虚假信息,建议利用AI生成反叙事内容应对威胁,但实验环境与真实场景存在差异。
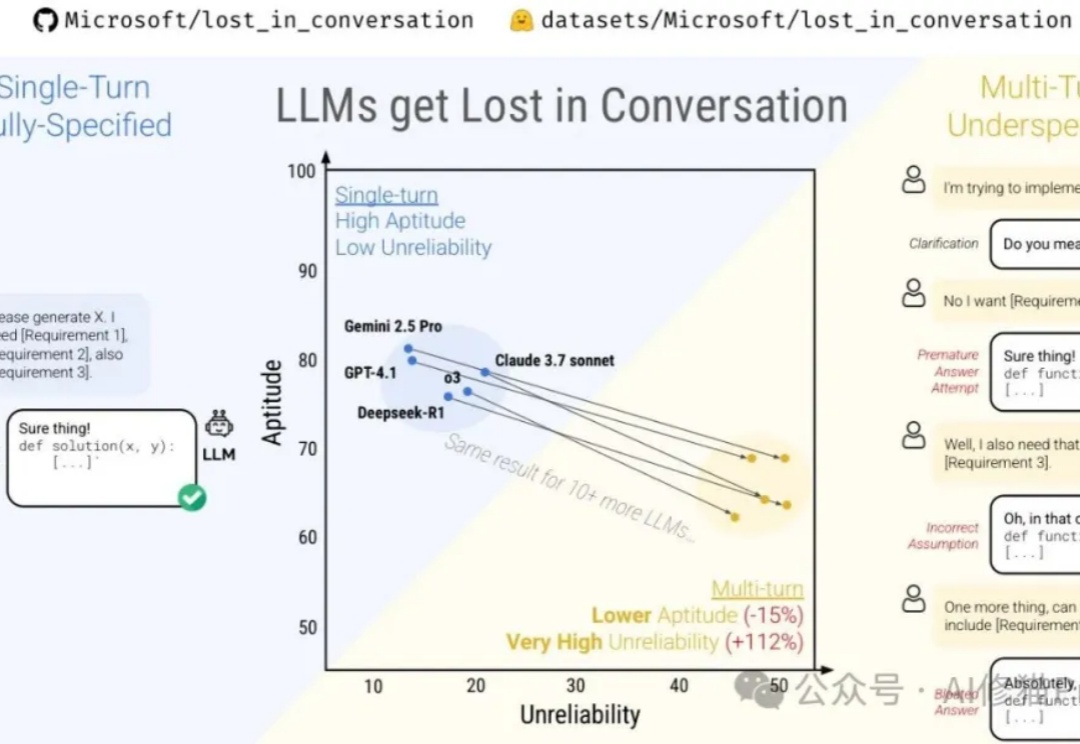
微软最近与Salesforce Research联合发布了一篇名为《Lost in Conversation》的研究,说当前最先进的LLM在多轮对话中表现会大幅下降,平均降幅高达39%。这一现象被称为对话中的"迷失"。文章分析了各大模型(包括Claude 3.7-Sonnet、Deepseek-R1等)在多轮对话中的表现差异,还解析了模型"迷失"的根本原因及有效缓解策略。