
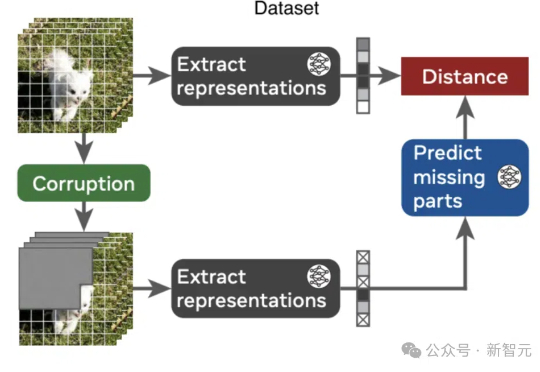
LeCun世界模型再近一步!Meta研究证明:AI可无先验理解直觉物理
LeCun世界模型再近一步!Meta研究证明:AI可无先验理解直觉物理AI如何理解物理世界?视频联合嵌入预测架构V-JEPA带来新突破,无需硬编码核心知识,在自监督预训练中展现出对直观物理的理解,超越了基于像素的预测模型和多模态LLM。
来自主题: AI技术研报
9369 点击 2025-03-02 15:47
AI如何理解物理世界?视频联合嵌入预测架构V-JEPA带来新突破,无需硬编码核心知识,在自监督预训练中展现出对直观物理的理解,超越了基于像素的预测模型和多模态LLM。
从本质上讲,LLM会根据用户从UI的输入生成代码示例。然后,生成的代码会通过中间件逻辑进行处理,根据逻辑跟踪文件、代码更改和第三方API调用。
近年来,大型语言模型(LLMs)在代码相关的任务上展现了惊人的表现,各种代码大模型层出不穷。这些成功的案例表明,在大规模代码数据上进行预训练可以显著提升模型的核心编程能力。
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。
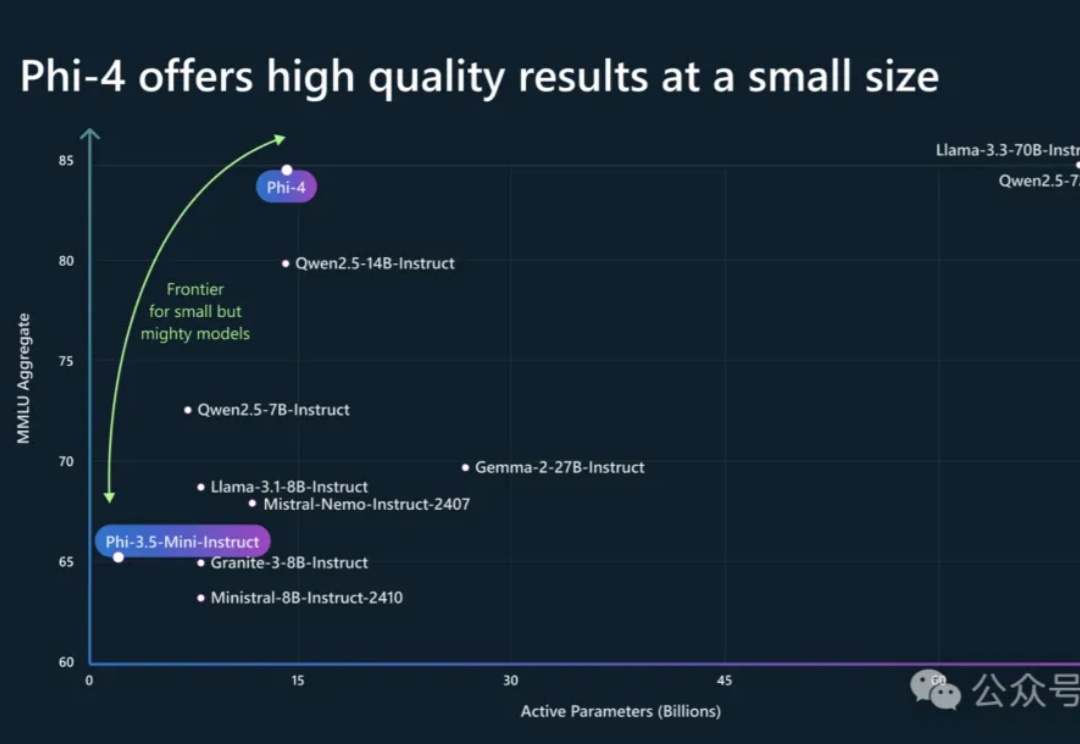
Phi-4系列模型上新了!56亿参数Phi-4-multimodal集语音、视觉、文本多模态于一体,读图推理性能碾压GPT-4o;另一款38亿参数Phi-4-mini在推理、数学、编程等任务中超越了参数更大的LLM,支持128K token上下文。

当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。
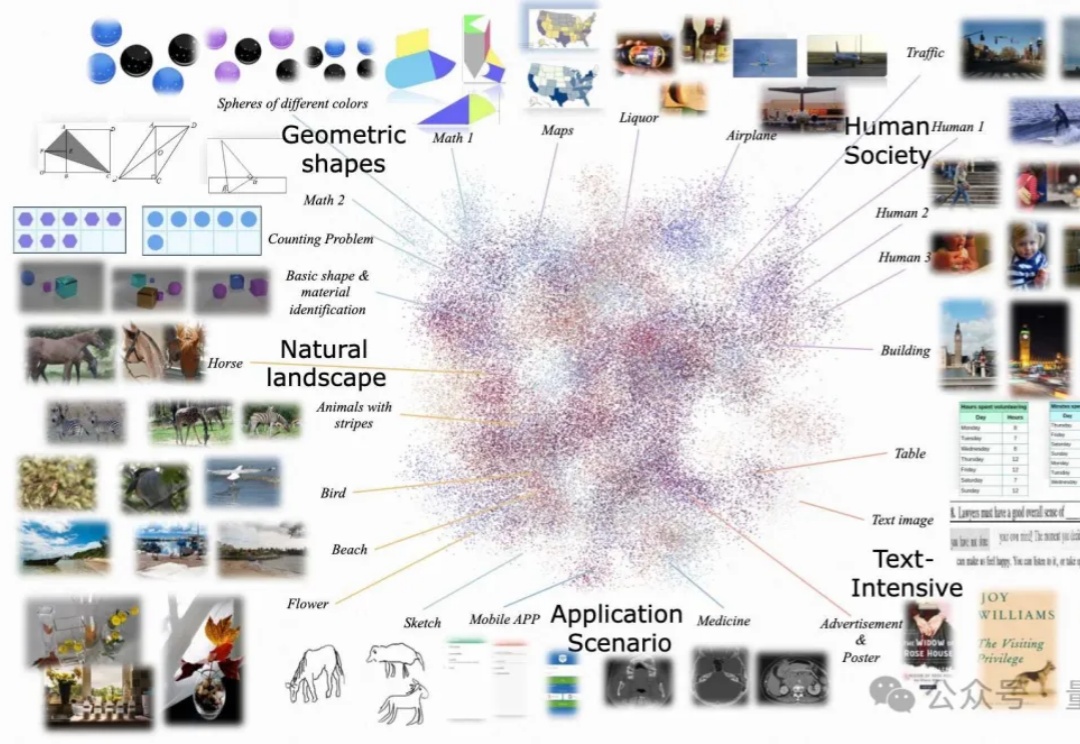
尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。

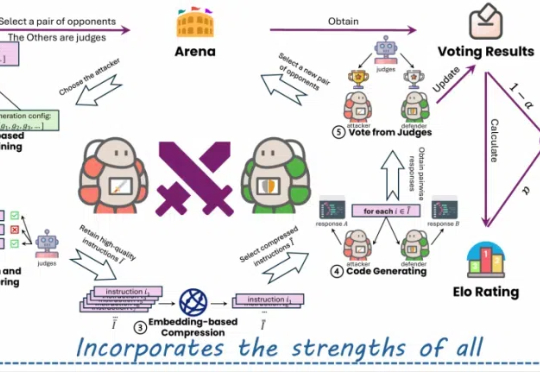
本文深入解析一项开创性研究——"Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning",该研究通过基于规则的强化学习技术显著提升了语言模型的推理能力。微软亚洲的研究团队受DeepSeek-R1成功经验的启发,利用结构化的逻辑谜题作为训练场,为模型创建了一个可以系统学习和改进推理技能的环境。
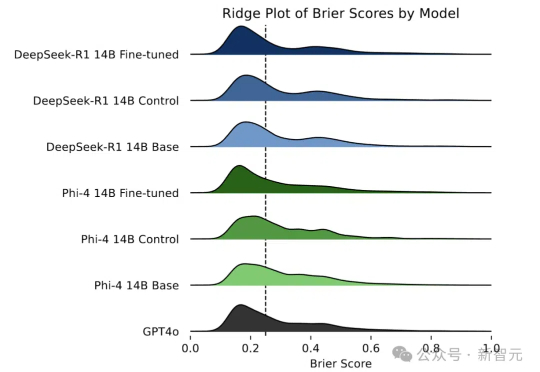
还在惊叹预言家的神奇?如今LLM也掌握了预测未来的「超能力」!研究人员通过自我博弈和直接偏好优化,让LLM摆脱人工数据依赖,大幅提升预测能力。

“放弃生成式模型,不研究LLM(大语言模型),我们没办法只通过文本训练让AI达到人类的智慧水平。”近日,Meta首席AI科学家杨立昆(Yann LeCun)在法国巴黎的2025年人工智能行动峰会上再一次炮轰了生成式AI。