

日本AI研究第一人这样评价Deepseek
日本AI研究第一人这样评价Deepseek中国初创企业DeepSeek(深度求索)开发的高性能、低成本生成式AI(人工智能)大规模语言模型(LLM)受到了全世界的关注。日本经济新闻(中文版:日经中文网)就如何评价该公司的最新AI模型、安全性方面的风险、以及对日本企业的影响等问题,采访了日本AI研究领域的第一人、东京大学教授松尾丰。
来自主题: AI资讯
8248 点击 2025-02-17 09:55
中国初创企业DeepSeek(深度求索)开发的高性能、低成本生成式AI(人工智能)大规模语言模型(LLM)受到了全世界的关注。日本经济新闻(中文版:日经中文网)就如何评价该公司的最新AI模型、安全性方面的风险、以及对日本企业的影响等问题,采访了日本AI研究领域的第一人、东京大学教授松尾丰。

近年来,多模态大模型(MLLM)在视觉理解领域突飞猛进,但如何让大语言模型(LLM)低成本掌握视觉生成能力仍是业界难题!

全球有多少AI算力?算力增长速度有多快?在这场AI「淘金热」中,都有哪些新「铲子」?AI初创企业Epoch AI发布了最新全球硬件估算报告。
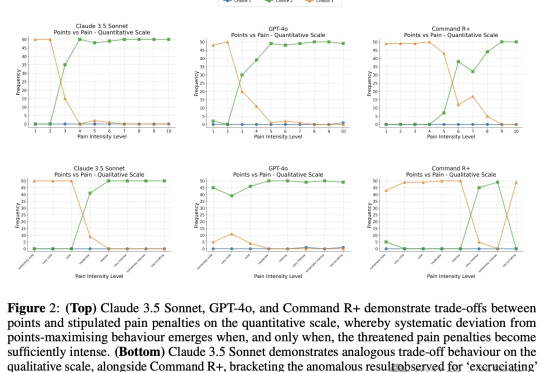
以大语言模型为代表的AI在智力方面已经逐渐逼近甚至超过人类,但能否像人类一样有痛苦、快乐这样的感知呢?近日,谷歌团队和LSE发表了一项研究,他们发现,LLM能够做出避免痛苦的权衡选择,这也许是实现「有意识AI」的第一步。
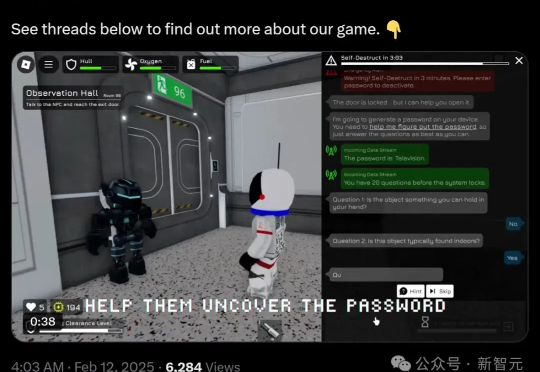
还在用枯燥的数学题和编程题测试AI?落伍啦!现在,打游戏就能测出AI的真实力。GameArena团队打造的Roblox新游《AI空间逃脱》,让你在紧张刺激的密室逃脱中,顺便就把AI模型的推理能力给评估了。这不仅比传统测试方法更有趣,还能生成宝贵的游戏数据,帮助开发者更全面地了解AI的强项与短板。
复旦新研究揭示了AI系统自我复制的突破性进展,表明当前的LLM已具备在没有人类干预的情况下自我克隆的能力。这不仅是AI超越人类的一大步,也为「流氓AI」埋下了隐患,带来前所未有的安全风险。

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。
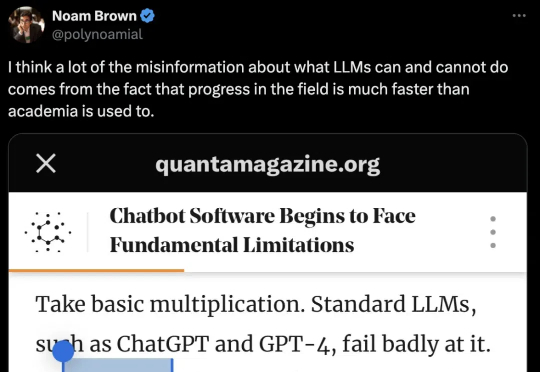
一篇报道,在AI圈掀起轩然大波。文中引用了近2年前的论文直击大模型死穴——Transformer触及天花板,却引来OpenAI研究科学家的紧急回应。谁能想到,一篇于2023年发表的LLM论文,竟然在一年半之后又「火」了。
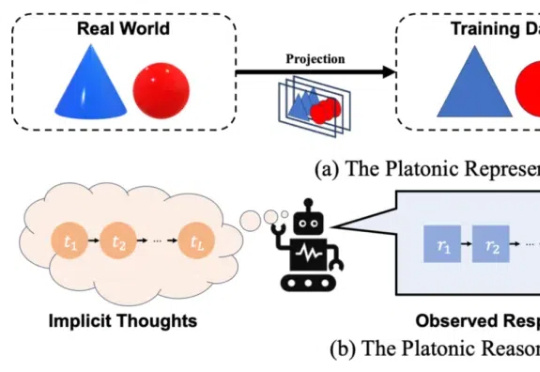
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。
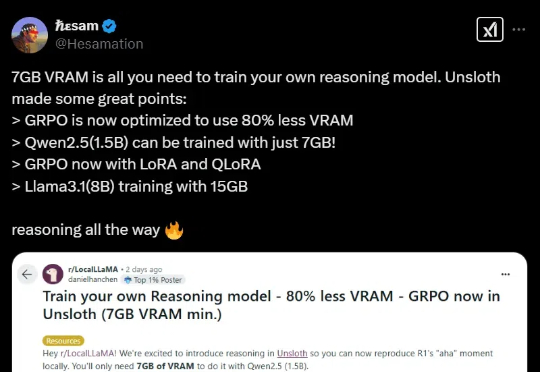
黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。