
Bengio、LeCun再喊话:AGI推理不需要先学语言,LLM路走窄了?
Bengio、LeCun再喊话:AGI推理不需要先学语言,LLM路走窄了?Yoshua Bengio最近在《金融时报》的专栏文章中表示,「AI可以在说话之前学会思考」,实现内部的深思熟虑将成为AGI道路的里程碑。无独有偶,就在几个月前,Yann LeCun也多次表达过类似的观点。
来自主题: AI资讯
7306 点击 2024-12-06 10:00
Yoshua Bengio最近在《金融时报》的专栏文章中表示,「AI可以在说话之前学会思考」,实现内部的深思熟虑将成为AGI道路的里程碑。无独有偶,就在几个月前,Yann LeCun也多次表达过类似的观点。
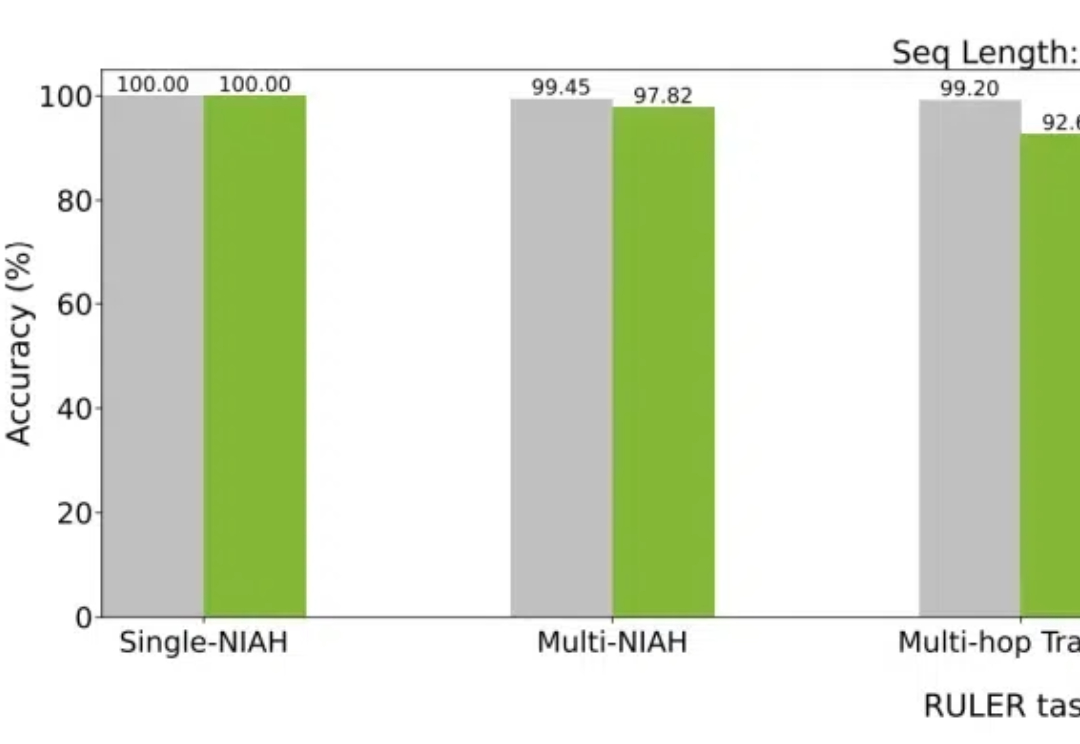
大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。
评估和评价长期以来一直是人工智能 (AI) 和自然语言处理 (NLP) 中的关键挑战。然而,传统方法,无论是基于匹配还是基于词嵌入,往往无法判断精妙的属性并提供令人满意的结果。

LLM在推理时,竟是通过一种「程序性知识」,而非照搬答案?可以认为这是一种变相的证明:LLM的确具备某种推理能力。然而存在争议的是,这项研究只能提供证据,而非证明。
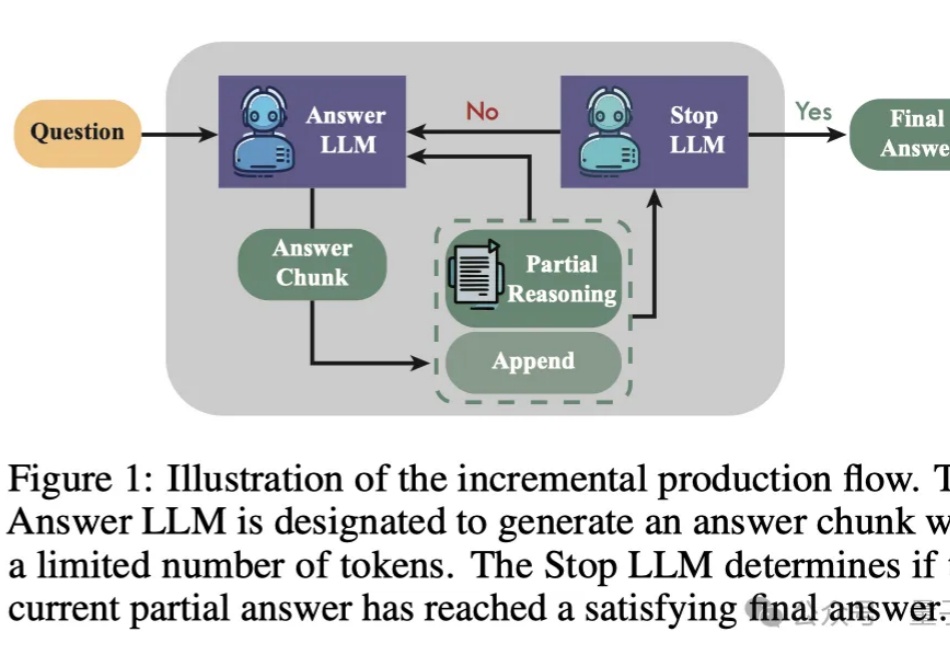
提升LLM数学能力的新方法来了——
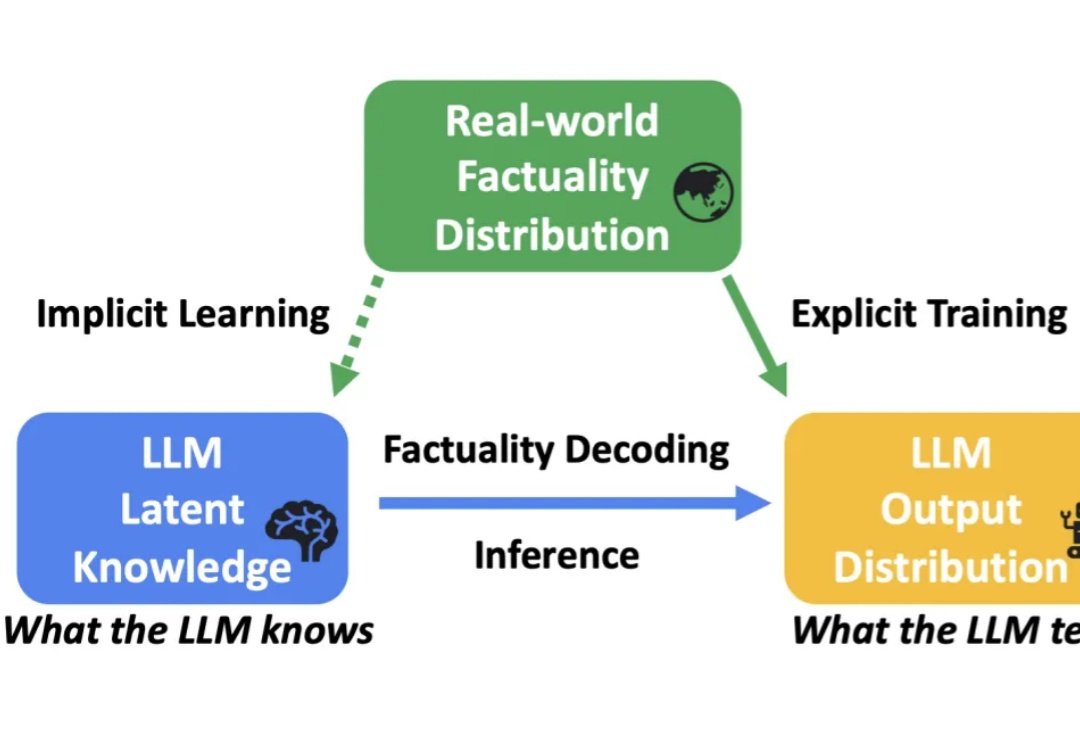
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。

对于LLM来说,人类语言可能不是最好的交流媒介,正如《星战》中的机器人有自己的一套语言,近日,来自微软的研究人员改进了智能体间的交互方式,使模型的通信速度翻倍且不损失精度。

教育一直被认为是会被LLM改变最大的行业之一。ChatGPT 的使用场景中,教育占据了很大比重,其用量常随开学和假期规律波动。而 Andrej Karpathy 也选择了教育作为他的创业方向。人们都期待能够有全能的AI Tutor,因材施教,提供给每个人最好、最个性化的教育。
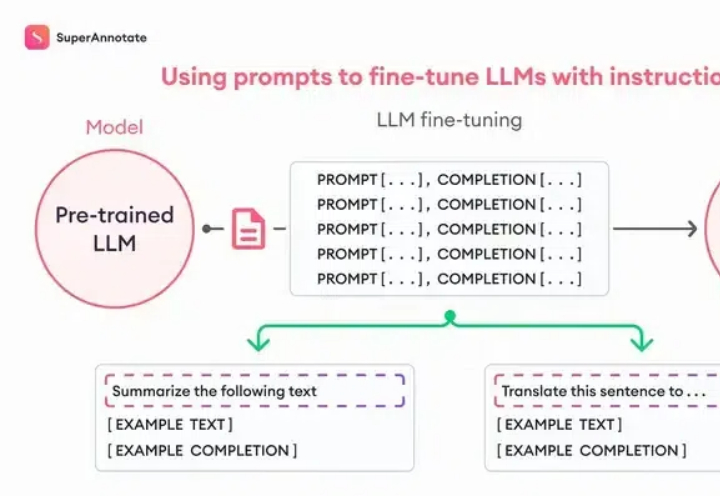
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。

LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。