
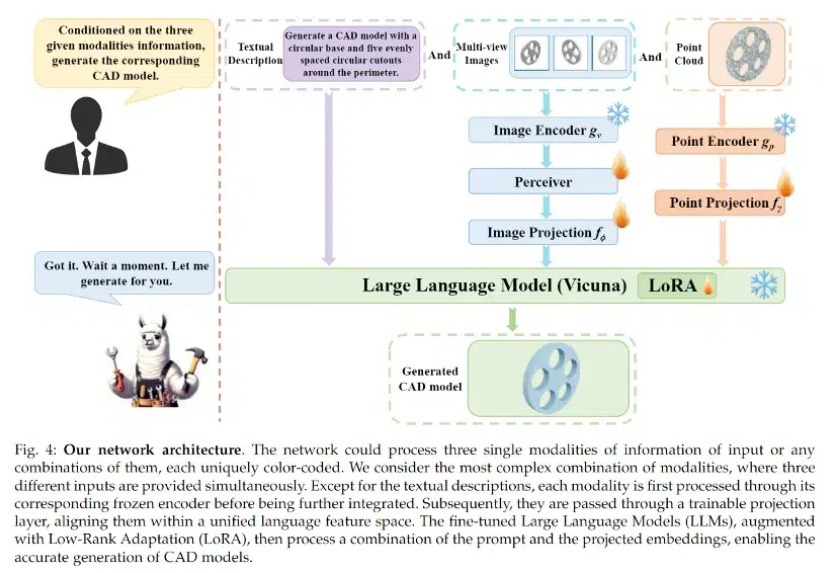
文本、图像、点云任意模态输入,AI能够一键生成高质量CAD模型了
文本、图像、点云任意模态输入,AI能够一键生成高质量CAD模型了该项目由忆生科技联合香港大学、上海科技大学共同完成,是全球首个同时支持文本描述、图像、点云等多模态输入的计算机辅助设计(CAD)生成大模型。
来自主题: AI技术研报
6753 点击 2024-11-25 15:51
该项目由忆生科技联合香港大学、上海科技大学共同完成,是全球首个同时支持文本描述、图像、点云等多模态输入的计算机辅助设计(CAD)生成大模型。
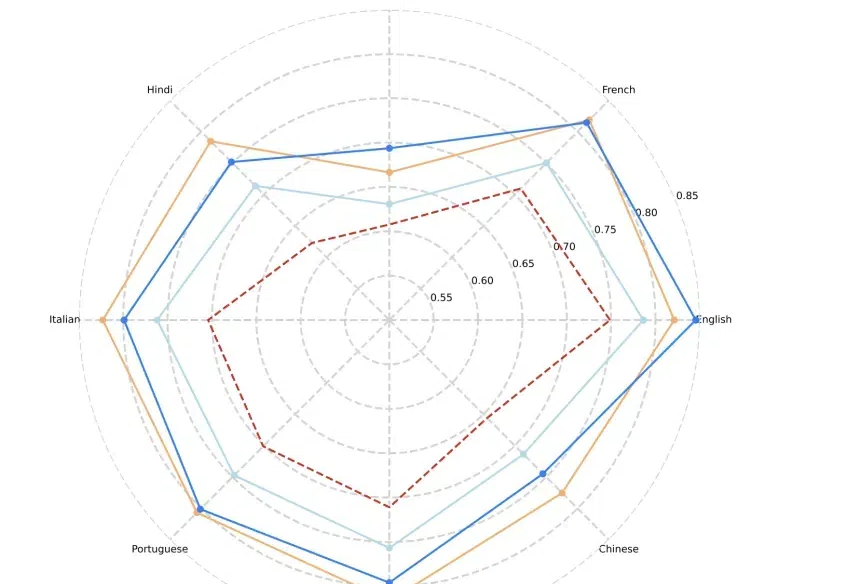
Meta全新发布的基准Multi-IF涵盖八种语言、4501个三轮对话任务,全面揭示了当前LLM在复杂多轮、多语言场景中的挑战。所有模型在多轮对话中表现显著衰减,表现最佳的o1-preview模型在三轮对话的准确率从87.7%下降到70.7%;在非拉丁文字语言上,所有模型的表现显著弱于英语。
最近,Meta Gen AI 部门的数据科学总监 Rohit Patel 听到了你的心声。他用加法和乘法 —— 小学二年级的数学知识,深入浅出地解析了大模型的基础原理。

Hugging Face 上的模型数量已经超过了 100 万。但是几乎每个模型都是孤立的,难以与其它模型沟通。尽管有些研究者甚至娱乐播主试过让 LLM 互相交流,但所用的方法大都比较简单。
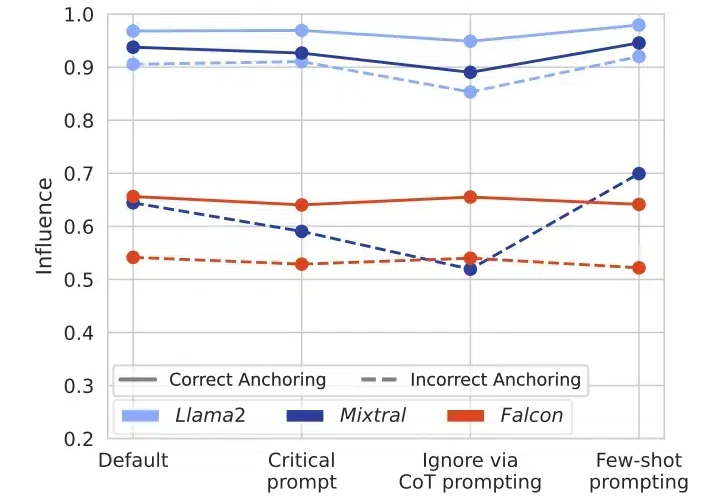
在当今人工智能迅猛发展的时代,大语言模型(LLMs)已成为众多AI应用的核心引擎。然而,来自ETH Zurich和Google DeepMind的一项最新研究揭示了一个令人深思的现象:这些看似强大的模型存在着严重的“盲从效应”。
我们对小型语言模型的增强方法、已存在的小模型、应用、与 LLMs 的协作、以及可信赖性方面进行了详细调查。
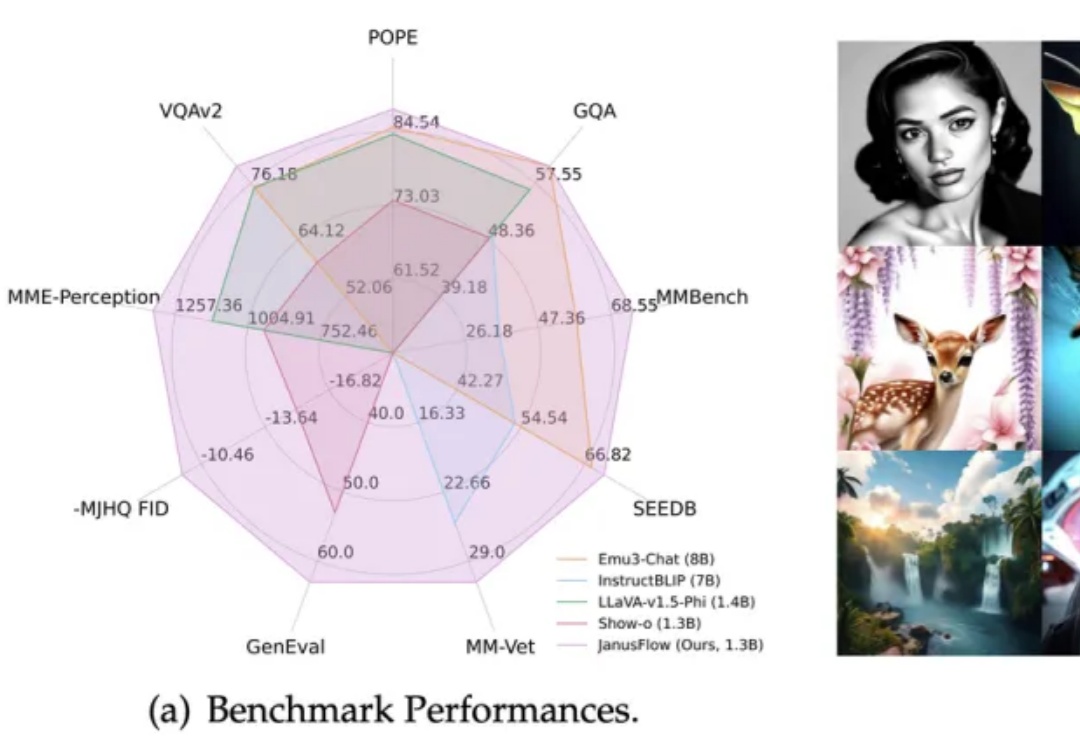
在多模态AI领域,基于预训练视觉编码器与MLLM的方法(如LLaVA系列)在视觉理解任务上展现出卓越性能。
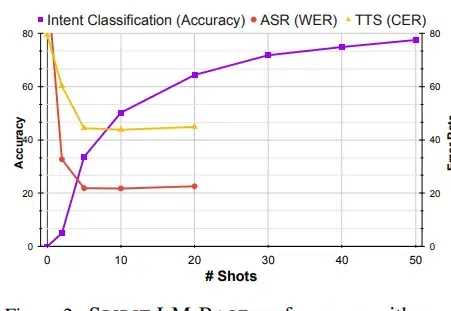
Meta最近开源了一个7B尺寸的Spirit LM的多模态语言模型,能够理解和生成语音及文本,可以非常自然地在两种模式间转换,不仅能处理基本的语音转文本和文本转语音任务,还能捕捉和再现语音中的情感和风格。

Scaling Law撞墙,扩展语言智能体的推理时计算实在太难了!破局之道,竟是使用LLM作为世界模型?OSU华人团队发现,使用GPT-4o作为世界模型来支持复杂环境中的规划,潜力巨大。
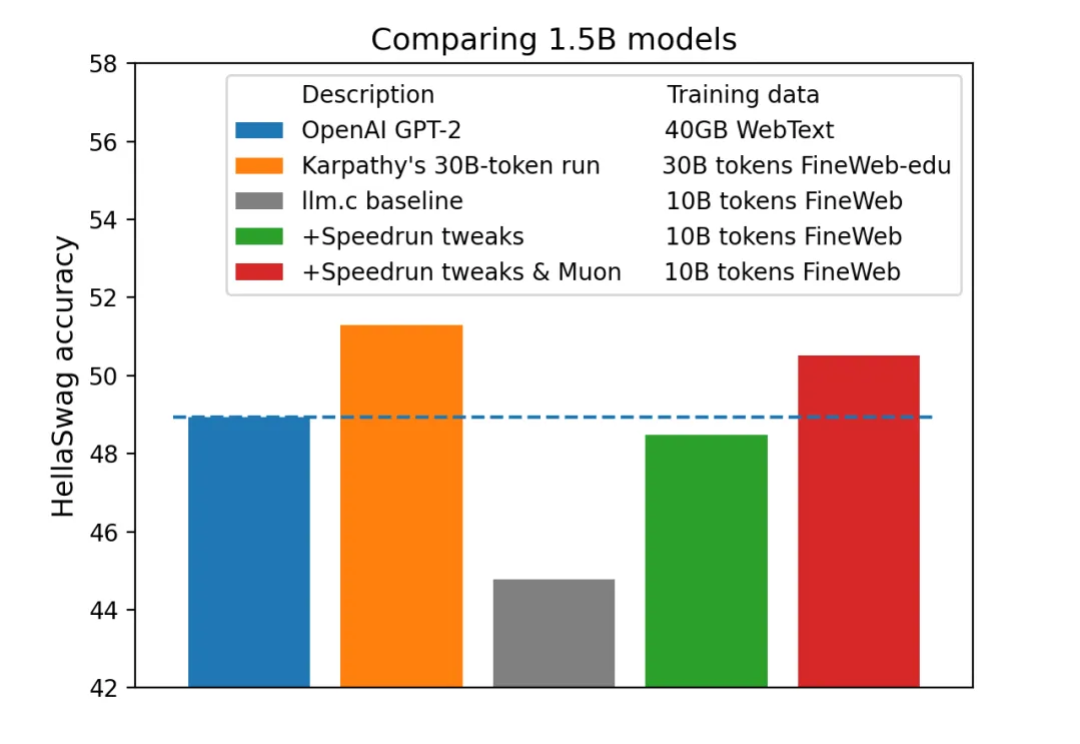
今年 4 月,AI 领域大牛 Karpathy 一个仅用 1000 行代码即可在 CPU/fp32 上实现 GPT-2 训练的项目「llm.c」曾经引发机器学习社区的热烈讨论。