

LLM对齐综述|迈向可扩展的大模型自动对齐,中科院软件所&阿里千问发布
LLM对齐综述|迈向可扩展的大模型自动对齐,中科院软件所&阿里千问发布近年来,大模型的高速发展极大地改变了人工智能的格局。对齐(Alignment) 是使大模型的行为符合人类意图和价值观,引导大模型按照人类的需求和期望进化的核心步骤,因此受到学术界和产业界的高度关注。
来自主题: AI资讯
8302 点击 2024-09-12 10:10
近年来,大模型的高速发展极大地改变了人工智能的格局。对齐(Alignment) 是使大模型的行为符合人类意图和价值观,引导大模型按照人类的需求和期望进化的核心步骤,因此受到学术界和产业界的高度关注。

近段时间,AI 编程工具 Cursor 的风头可说是一时无两,其表现卓越、性能强大。近日,Cursor 一位重要研究者参与的一篇相关论文发布了,其中提出了一种方法,可通过搜索自然语言的规划来提升 Claude 3.5 Sonnet 等 LLM 的代码生成能力。
近日,一篇关于自动化 AI 研究的论文引爆了社交网络,原因是该论文得出了一个让很多人都倍感惊讶的结论:LLM 生成的想法比专家级人类研究者给出的想法更加新颖!

上下文学习(In-Context Learning, ICL)是指LLMs能够仅通过提示中给出的少量样例,就迅速掌握并执行新任务的能力。这种“超能力”让LLMs表现得像是一个"万能学习者",能够在各种场景下快速适应并产生高质量输出。然而,关于ICL的内部机制,学界一直存在争议。

与 Text2SQL 或 RAG 不同,TAG 充分利用了数据库系统和 LLM 的功能。

人工设计提示词太麻烦了!想过让 LLM 帮你设计用于 LLM 的提示词吗?

如果可以使用世界上所有的算力来训练AI模型,会怎么样?近日,凭借发布了开源的Hermes 3(基于Llama 3.1)而引起广泛关注的Nous Research,再次宣布了一项重大突破——DisTrO(分布式互联网训练)。

高端的食材,往往只需要最朴素的烹饪方式;高端的提示词也一样,把Top-K写进来,一个专属于你的CoT-decoding解码策略应运而生!丝毫不要怀疑LLM的推理能力,在这个维度上,它比我们懂!
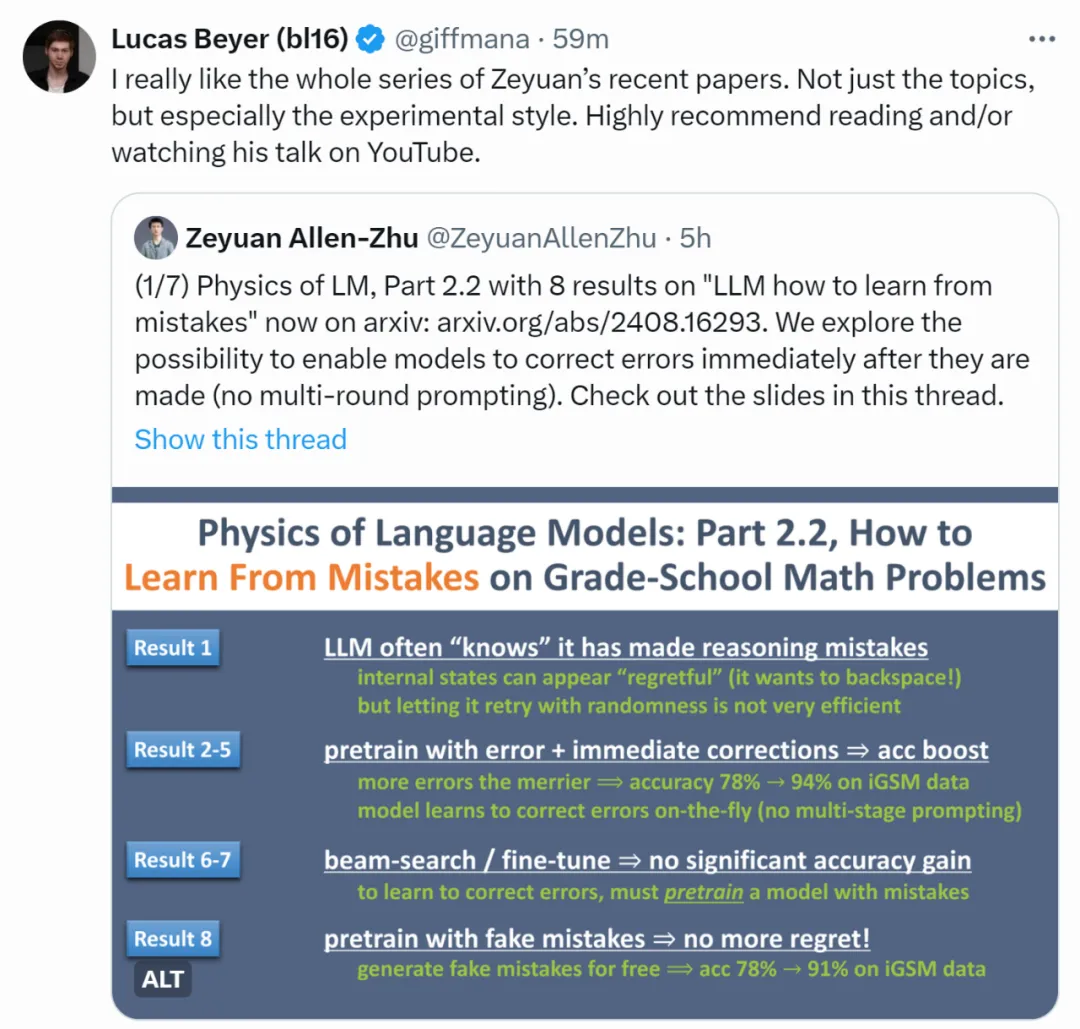
即便是最强大的语言模型(LLM),仍会偶尔出现推理错误。除了通过提示词让模型进行不太可靠的多轮自我纠错外,有没有更系统的方法解决这一问题呢?

提示工程师Riley Goodside小哥,依然在用「Strawberry里有几个r」折磨大模型们,GPT-4o在无限次PUA后,已经被原地逼疯!相比之下,Claude坚决拒绝PUA,是个大聪明。而谷歌最近的论文也揭示了本质原因:LLM没有足够空间,来存储计数向量。