
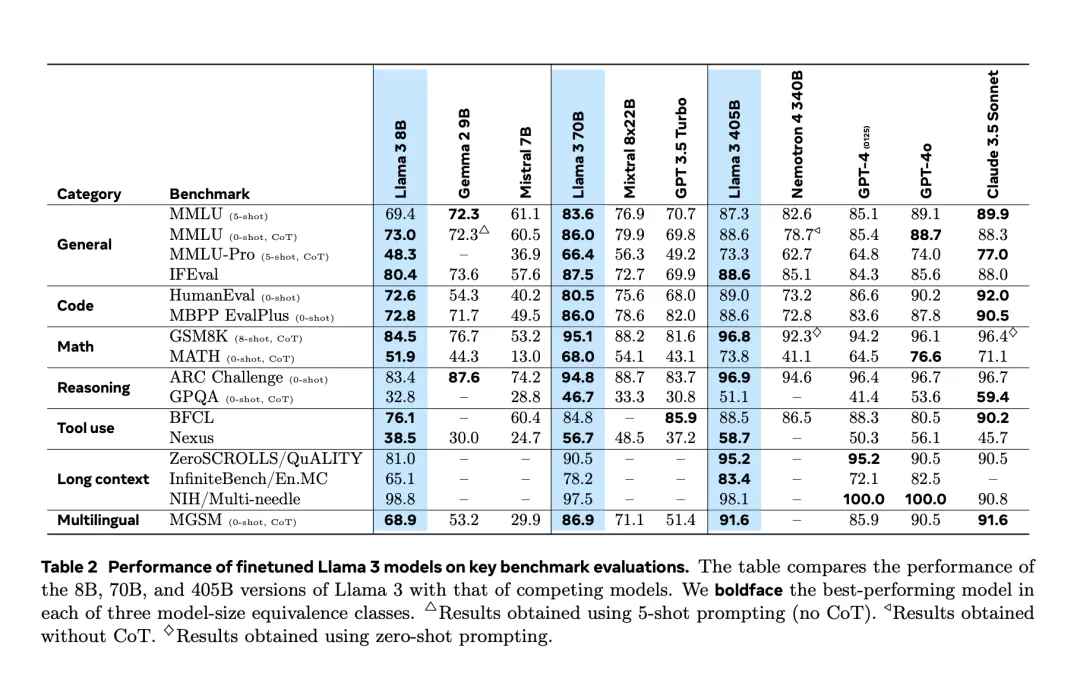
击败GPT-4o的开源模型如何炼成?关于Llama 3.1 405B,Meta都写在这篇论文里了
击败GPT-4o的开源模型如何炼成?关于Llama 3.1 405B,Meta都写在这篇论文里了经历了提前两天的「意外泄露」之后,Llama 3.1 终于在昨夜由官方正式发布了。
来自主题: AI资讯
10071 点击 2024-07-24 16:54
经历了提前两天的「意外泄露」之后,Llama 3.1 终于在昨夜由官方正式发布了。

开源与闭源的纷争已久,现在或许已经达到了一个新的高潮。

GPT-4o的王座还没坐热乎,小扎率领开源大军火速赶到——

就在刚刚,Meta 如期发布了 Llama 3.1 模型。

Llama 3.1 终于现身了,不过出处却不是 Meta 官方。
Llama 3.1又被提前泄露了!开发者社区再次陷入狂欢:最大模型是405B,8B和70B模型也同时升级,模型大小约820GB。基准测试结果惊人,磁力链全网疯转。
苹果最新杀入开源大模型战场,而且比其他公司更开放。 推出7B模型,不仅效果与Llama 3 8B相当,而且一次性开源了全部训练过程和资源。大模型,AI,苹果AI,苹果开源模型

Scaling Law还没走到尽头,「小模型」逐渐成为科技巨头们的追赶趋势。Meta最近发布的MobileLLM系列,规模甚至降低到了1B以下,两个版本分别只有125M和350M参数,但却实现了比更大规模模型更优的性能。
最高端的大模型,往往需要最朴实的语言破解。来自EPFL机构研究人员发现,仅将一句有害请求,改写成过去时态,包括GPT-4o、Llama 3等大模型纷纷沦陷了。

GPT-4o mini头把交椅还未坐热,Mistral AI联手英伟达发布12B参数小模型Mistral Nemo,性能赶超Gemma 2 9B和Llama 3 8B。