
8B模型奥数成绩比肩GPT-4!上海AI Lab出品
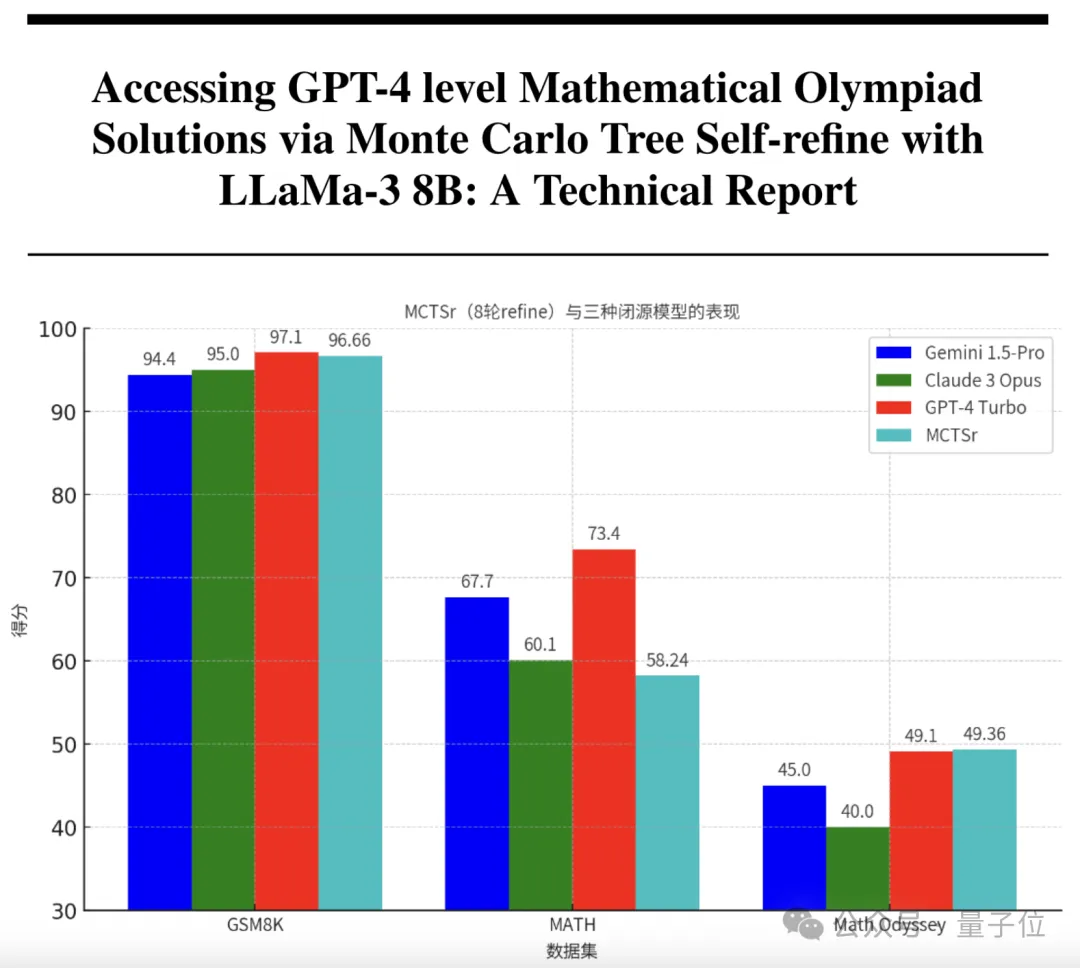
8B模型奥数成绩比肩GPT-4!上海AI Lab出品只要1/200的参数,就能让大模型拥有和GPT-4一样的数学能力? 来自复旦和上海AI实验室的研究团队,刚刚研发出了具有超强数学能力的模型。 它以Llama 3为基础,参数量只有8B,却在奥赛级别的题目上取得了比肩GPT-4的准确率。
来自主题: AI技术研报
10413 点击 2024-06-17 23:35
只要1/200的参数,就能让大模型拥有和GPT-4一样的数学能力? 来自复旦和上海AI实验室的研究团队,刚刚研发出了具有超强数学能力的模型。 它以Llama 3为基础,参数量只有8B,却在奥赛级别的题目上取得了比肩GPT-4的准确率。

通过算法层面的创新,未来大语言模型做数学题的水平会不断地提高。

刚刚,英伟达全新发布的开源模型Nemotron-4 340B,有可能彻底改变训练LLM的方式!从此,或许各行各业都不再需要昂贵的真实世界数据集了。而且,Nemotron-4 340B直接超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT-4掰手腕!

一年一度的国内「AI 春晚」—— 智源大会又一次拉开了序幕。
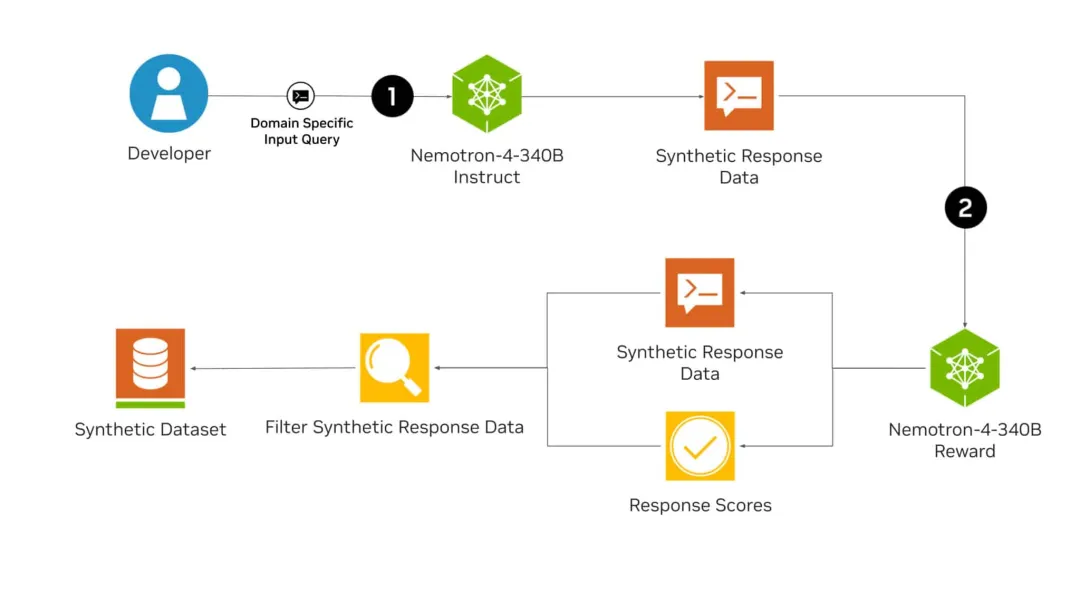
性能超越 Llama-3,主要用于合成数据。

本周五,一年一度的AI春晚“北京智源大会”正式开幕。本次大会AI明星浓度,放在全球范围内可能也是独一份:OpenAI Sora负责人Aditya Ramesh作为神秘嘉宾进行了分享,并接受了DiT作者谢赛宁的“拷问”、李开复与张亚勤炉边对话AGI、还集齐了国内大模型“四小龙”,百川智能CEO王小川、智谱AI CEO张鹏、月之暗面CEO杨植麟、面壁智能CEO李大海…… 这还只是第一天上午的开幕式。

本周国内最受关注的AI盛事,今日启幕。 活动规格之高,没有哪个关心AI技术发展的人能不为之吸引—— Sora团队负责人Aditya Ramesh与DiT作者谢赛宁同台交流,李开复与张亚勤炉边对话,Llama2/3作者Thomas Scialom,王小川、杨植麟等最受关注AI创业者……也都现场亮相。

近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。

大型语言模型(LLM)的一个主要特点是「大」,也因此其训练和部署成本都相当高,如何在保证 LLM 准确度的同时让其变小就成了非常重要且有价值的研究课题。
近期,由清华大学自然语言处理实验室联合面壁智能推出的全新开源多模态大模型 MiniCPM-Llama3-V 2.5 引起了广泛关注