
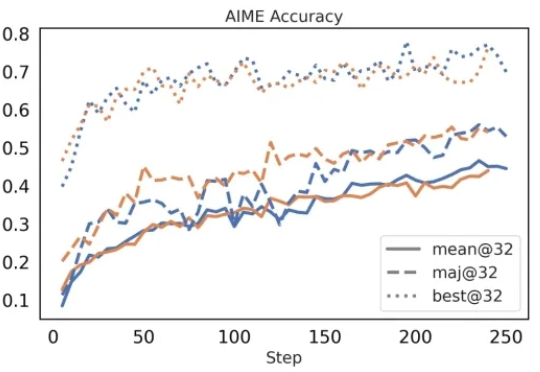
让强化学习快如闪电:FlashRL一条命令实现极速Rollout,已全部开源
让强化学习快如闪电:FlashRL一条命令实现极速Rollout,已全部开源在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
来自主题: AI技术研报
8397 点击 2025-08-13 11:27
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。

中国自研世界模型Matrix-3D只需单张图就能生成可自由探索的3D世界,不仅效果对标李飞飞的World Labs,而且还能实现更大范围的探索空间,率先进入AI理解世界的前沿领域。
近年来,文生图模型(Text-to-Image Models)飞速发展,从早期的 GAN 架构到如今的扩散和自回归模型,生成图像的质量和细节表现力实现了跨越式提升。这些模型大大降低了高质量图像创作的门槛,为设计、教育、艺术创作等领域带来了前所未有的便利。

据知情人士透露,风投公司Andreessen Horowitz 已同意牵头向材料科学人工智能初创公司 Periodic Labs 投资 2 亿美元。

做出AI时代的LABUBU,成了大厂们的目标之一。不过就AI玩具来说,技术是加分项,但并不是核心。想做出下一个LABUBU,要在技术成本和情感溢价中找到平衡。 在2025年下半年,大厂的AI争夺战已经卷到了玩具上。
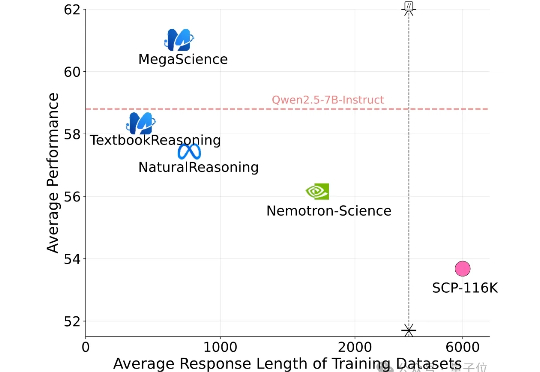
有史规模最大的开源科学推理后训练数据集来了! 上海创智学院、上海交通大学(GAIR Lab)发布MegaScience。该数据集包含约125万条问答对及其参考答案,广泛覆盖生物学、化学、计算机科学、经济学、数学、医学、物理学等多个学科领域,旨在为通用人工智能系统的科学推理能力训练与评估提供坚实的数据。
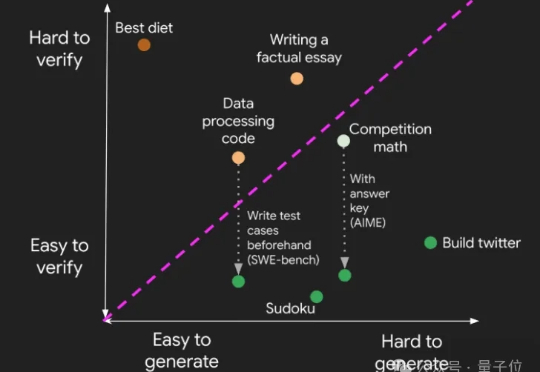
当大模型把人类曾经的终极考题变成日常练习,AI的奔跑却悄悄瘸了腿—— 训练能力突飞猛进,验证答案的本事却成了拖后腿的短板。 为此,上海AI Lab和澳门大学联合发布通用答案验证模型CompassVerifier与评测集VerifierBench。填补了Verifier领域没有建立验证->提升->验证的循环迭代体系的空白。
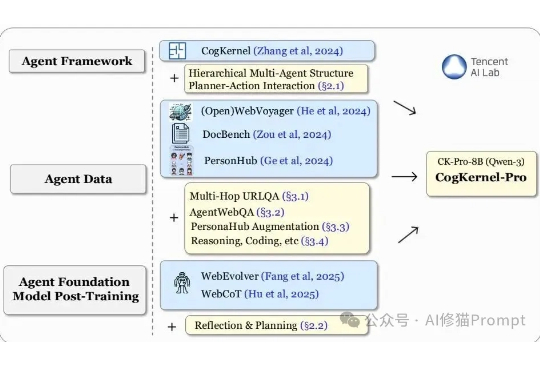
当AI智能体(Agent)开发的浪潮涌来,很多一线工程师却发现自己站在一个尴尬的十字路口:左边是谷歌、OpenAI等巨头深不可测的“技术黑盒”,右边是看似开放却暗藏“付费墙”的开源社区。大家空有场景和想法,却缺少一把能打开未来的钥匙。

7月底 Black Forest Labs 和 Krea 合作开发的高级文本到图像生成模型 Flux.1 Krea Dev,最近终于有时间进行测评了。Flux.1 Krea Dev 是基于FLUX.1 dev 模型进行蒸馏的,参数规模12B,专注于提升图像的美学和真实感,避免了常见的 AI 生成痕迹(过度饱和或不自然高光等等),更倾向于追求自然细节、照片级真实感和多样性。
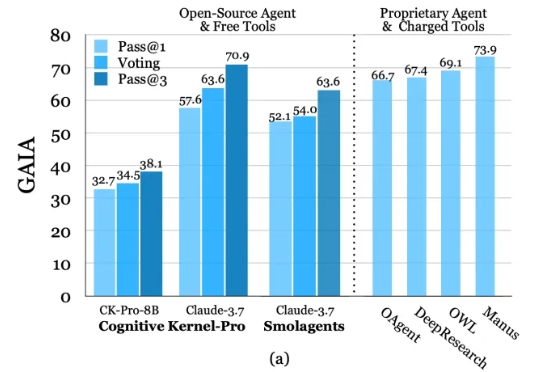
深度研究智能体(Deep Research Agents)凭借大语言模型(LLM)和视觉-语言模型(VLM)的强大能力,正在重塑知识发现与问题解决的范式。