
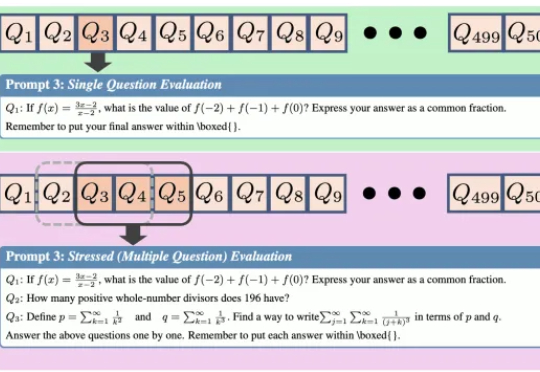
AI“压力面”,DeepSeek性能暴跌近30% | 清华&上海AI Lab
AI“压力面”,DeepSeek性能暴跌近30% | 清华&上海AI Lab给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。
来自主题: AI技术研报
10235 点击 2025-07-21 10:44
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。
2025 年 7 月 15 日,韩国游戏创企 Planetarium Labs 宣布,公司旗下 AI 游戏创作分享平台 Verse 8 已正式在 Web 端上线。根据 Planetarium Labs 介绍,在 AI 游戏开发助手 Agent 8 的辅助下,用户可以在 Verse 8 上利用自然语言开发、发行以及分享游戏,不需要下载和安装任何软件/资源。
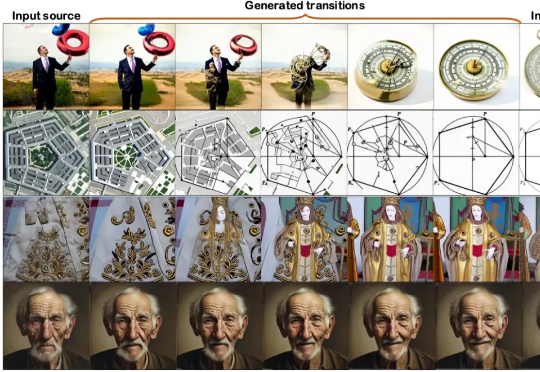
本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。

当前最强大的视觉语言模型(VLMs)虽然能“看图识物”,但在理解电影方面还不够“聪明”。

交易成了!OpenAI前CTO初创拿到了20亿种子轮融资,成立5个月公司估值冲到120亿美元。未来几个月,这个汇聚OpenAI顶尖大佬团队,将发布首个多模态AI产品,还会开源部分组件。
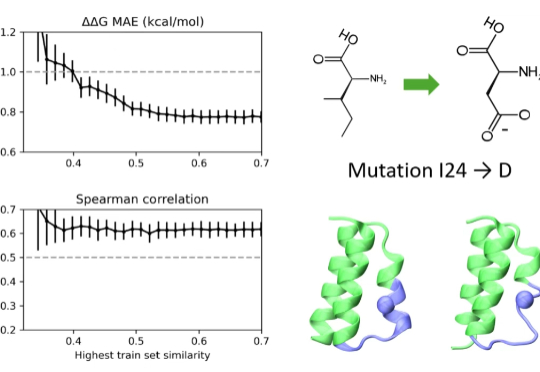
7 月 10 日,微软研究院 AI for Science 团队在《Science》杂志发表了题为「Scalable emulation of protein equilibrium ensembles with generative deep learning」的研究成果。
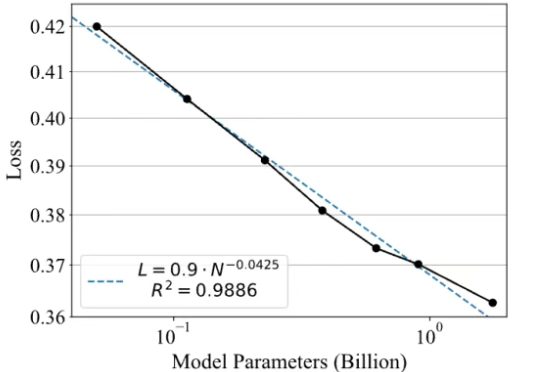
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
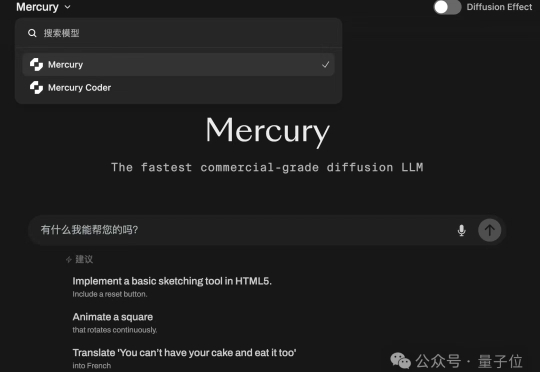
谁说扩散模型只能生成图像和视频?现在它们能高质量地写代码了,速度还比传统大模型更快!Inception Labs推出基于扩散技术的全新商业级大语言模型——Mercury。

Listen Labs 由两位哈佛校友 Florian Juengermann 与 Alfred Wahlforss 在 2024 年底联合创立,并在 2025 年 4 月连获 Sequoia 领投的种子轮与 A 轮合计 2700 万美元融资,目标是打造一套能自动招募受访者、主持上千场多语访谈、即时归档并复用洞察的“AI 用户研究员”体系。
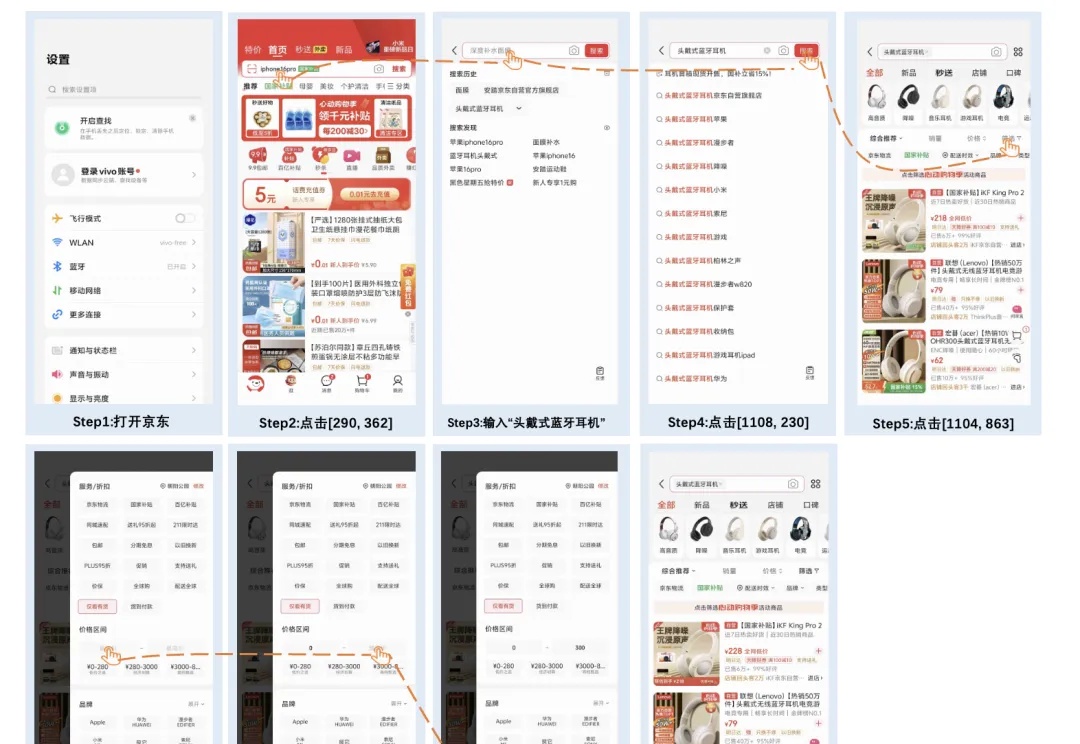
vivo AI Lab发布AI多模态新模型了,专门面向端侧设计,紧凑高效~