
10亿美金!李飞飞惊爆硅谷:英伟达AMD入局,3D空间革命开战
10亿美金!李飞飞惊爆硅谷:英伟达AMD入局,3D空间革命开战一次拿下10亿美金,惊爆硅谷!就在刚刚,李飞飞「明星初创」World Labs官宣:成功斩获高达10亿美元的全新一轮融资。此轮融资,投资人阵容堪称豪华——
来自主题: AI资讯
9809 点击 2026-02-20 13:54
一次拿下10亿美金,惊爆硅谷!就在刚刚,李飞飞「明星初创」World Labs官宣:成功斩获高达10亿美元的全新一轮融资。此轮融资,投资人阵容堪称豪华——
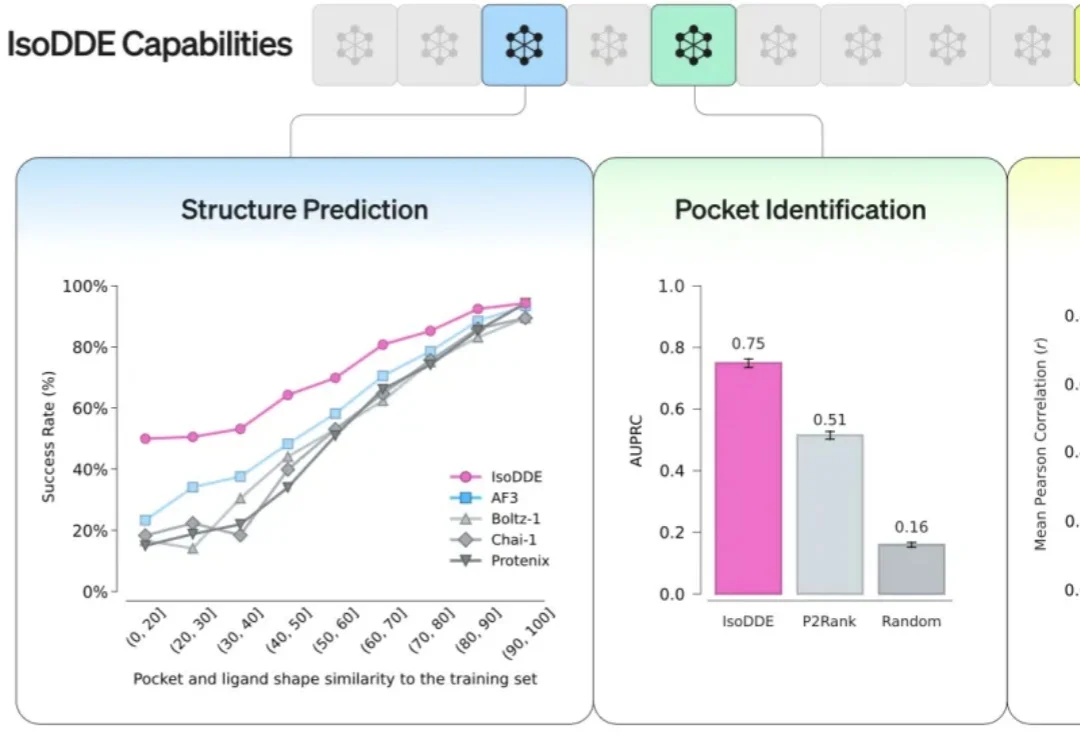
谷歌DeepMind和Isomorphic Labs合作,祭出了药物设计之王。
2026 马年注定迎来一个「AI 味」最浓的春节。
在十九世纪的暹罗王国曾诞生过这样一对连体兄弟:他们分别拥有完整的四肢和独立的大脑,但他们六十余年的人生被腰部相连着的一段不到十厘米的组织带永远绑定在了一起。他们的连体曾带来无尽的束缚,直到他们离开暹罗,走上马戏团的舞台。十年间,两兄弟以近乎合二为一的默契巡演欧美,获得巨大成功。
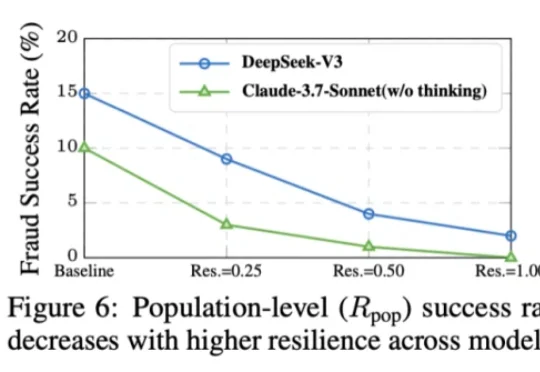
本⽂的主要作者来⾃上海交通⼤学和上海⼈⼯智能实验室,核⼼贡献者包括任麒冰、郑志杰、郭嘉轩,指导⽼师为⻢利庄⽼师和邵婧⽼师,研究⽅向为安全可控⼤模型和智能体。 最近,Moltbook 的爆⽕与随后的迅速
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?
陈丹琦首次转身工业界,第一站就选择Mira初创的理由找到了—— 有个赛友也在这儿,还足足“潜伏”了一年之久。
英国AI音频独角兽ElevenLabs宣布完成5亿美元(约合人民币34.7亿元)的D轮融资,估值达110亿美元(约合人民币763.5亿元)。其估值较去年年初的33亿美元,实现了超230%的飞速增长。ElevenLabs联合创始人兼CEO Mati Staniszewski还透露,该公司已在考虑IPO事宜。

据彭博社消息:李飞飞创办的World Labs正在以约50亿美元估值进行新一轮融资,融资规模最高可达5亿美元。如果融资完成:World Labs的估值将从2024年的10亿美元,直接乘5到50亿美元。

2026年1月,前OpenAI CTO Mira Murati创办的明星公司Thinking Machines Lab遭遇「灭顶之灾」:联合创始人Barret Zoph因办公室恋情丑闻被降职后心生不满,联合另外两名核心骨干向Mira逼宫索权,遭拒后被当场开除。然而仅不到一小时,三人便集体叛逃回OpenAI,在老东家的迎接下风光回朝。