
明星AI独角兽Mistral AI亮出大模型新王炸,代码和数学能力超群
明星AI独角兽Mistral AI亮出大模型新王炸,代码和数学能力超群Mistral AI两款全新7B模型宣战OpenAI,对标更长的代码分析和更高效的数学推理。
来自主题: AI资讯
6602 点击 2024-07-19 10:37
 搜索
搜索
Mistral AI两款全新7B模型宣战OpenAI,对标更长的代码分析和更高效的数学推理。
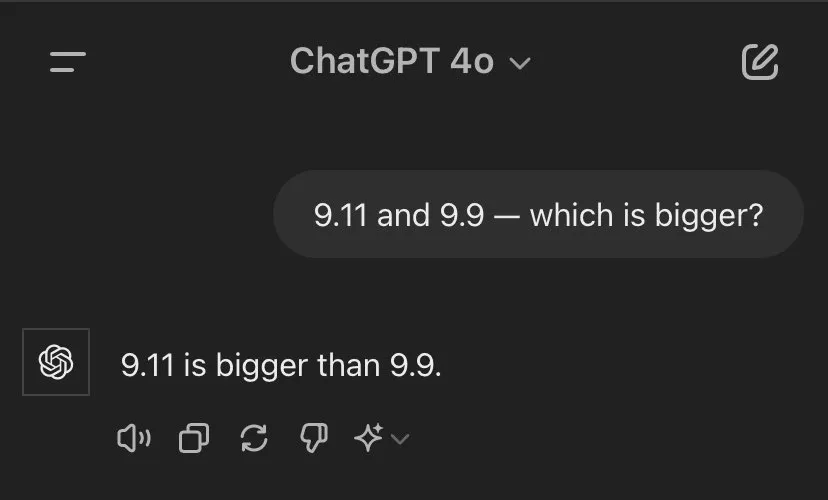
网友很好奇,Mathstral能不能搞定「9.11和9.9谁大」这一问题。

最近,7B小模型又成为了AI巨头们竞相追赶的潮流。继谷歌的Gemma2 7B后,Mistral今天又发布了两个7B模型,分别是针对STEM学科的Mathstral,以及使用Mamaba架构的代码模型Codestral Mamba。

“欧洲OpenAI”和“Transformer挑战者”强强联合了!

Mamba模型由于匹敌Transformer的巨大潜力,在推出半年多的时间内引起了巨大关注。但在大规模预训练的场景下,这两个架构还未有「一较高低」的机会。最近,英伟达、CMU、普林斯顿等机构联合发表的实证研究论文填补了这个空白。

时隔一年,FlashAttention又推出了第三代更新,专门针对H100 GPU的新特性进行优化,在之前的基础上又实现了1.5~2倍的速度提升。

超越Transformer和Mamba的新架构,刚刚诞生了。斯坦福UCSD等机构研究者提出的TTT方法,直接替代了注意力机制,语言模型方法从此或将彻底改变。
与 DeiT 等使用 ViT 和 Vision-Mamba (Vim) 方法的模型相比,ViL 的性能更胜一筹。

自 2017 年被提出以来,Transformer 已经成为 AI 大模型的主流架构,一直稳居语言建模方面 C 位。

Transformer挑战者、新架构Mamba,刚刚更新了第二代: