

Scale AI转向Meta后留市场空白,00后斯坦福肄业生抢微软等客户,已完成2.5亿元融资
Scale AI转向Meta后留市场空白,00后斯坦福肄业生抢微软等客户,已完成2.5亿元融资就在 Scale AI 公司的 95 后创始人 Alexandr Wang 在 Meta 挑大梁之际,他迎来了一位比他更小的 00 后劲敌。这名 00 后叫阿里·安萨里(Ali Ansari),是一名
来自主题: AI资讯
9588 点击 2025-09-15 08:35
就在 Scale AI 公司的 95 后创始人 Alexandr Wang 在 Meta 挑大梁之际,他迎来了一位比他更小的 00 后劲敌。这名 00 后叫阿里·安萨里(Ali Ansari),是一名
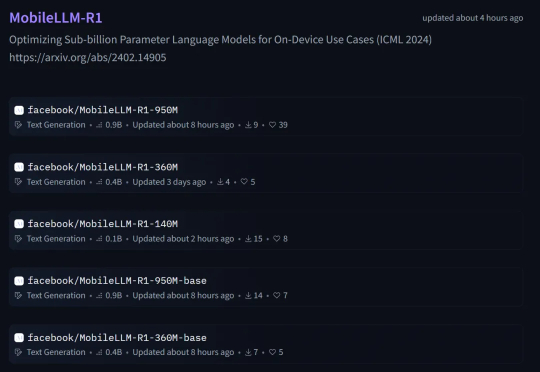
本周五,Meta AI 团队正式发布了 MobileLLM-R1。 这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。
Meta超级智能实验室(MSL)又被送上争议的风口浪尖了。

Meta 已签署一份价值超 1 亿美元的多年度合同,将使用 AI 图像初创公司 Black Forest Labs 的技术,这是这家社交媒体公司为扩展人工智能服务的最新投资。

Meta超级智能实验室的首篇论文,来了—— 提出了一个名为REFRAG的高效解码框架,重新定义了RAG(检索增强生成),最高可将首字生成延迟(TTFT)加速30倍。
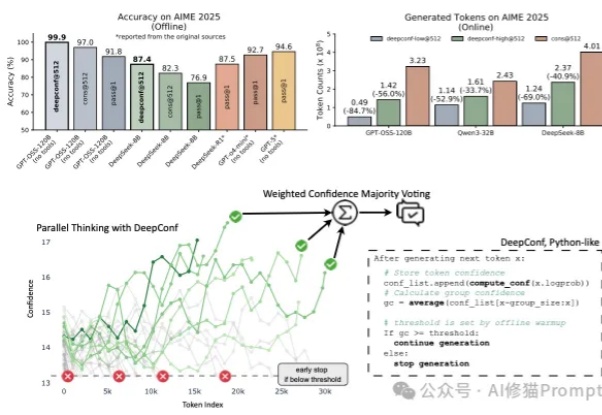
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。

经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。

Meta豪掷143亿收购Scale AI,意外成就了3名22岁青年的创业神话!他们靠着为OpenAI等顶级AI实验室输送模型专家训练师,干出百亿独角兽Mercor,年入1亿美金。目前,Mercor在《福布斯》Cloud 100 榜单中排名第89位。
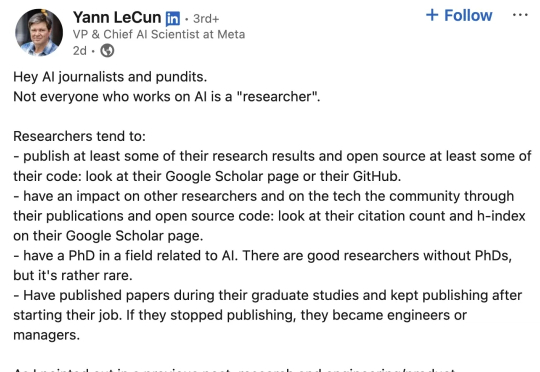
Meta内讧大戏再升级!首席AI官Alexandr Wang审核图灵奖大佬论文,LeCun亲自发帖疑似暗讽28岁新上司。没有PhD、没开源代码、没发表论文,都称不上AI研究员。
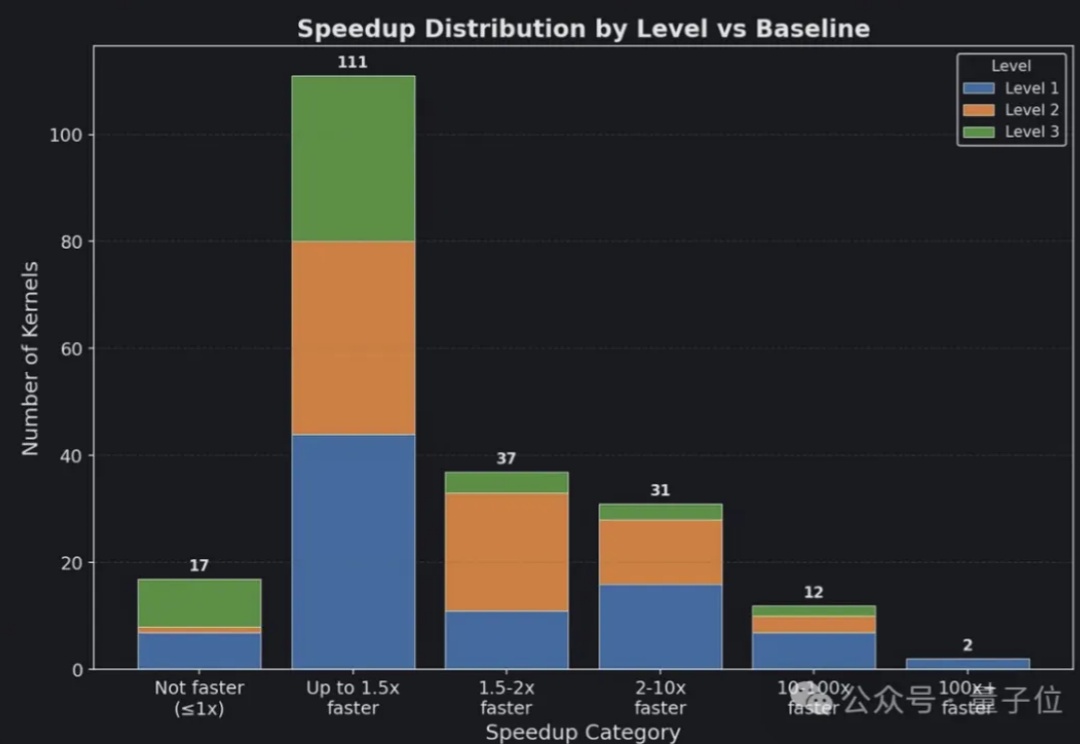
AI自动生成的苹果芯片Metal内核,比官方的还要好?