

Le Chat全方面对标ChatGPT,欧洲AI新贵穷追不舍
Le Chat全方面对标ChatGPT,欧洲AI新贵穷追不舍最近几个月,由谷歌和 Meta 前研究人员建立的欧洲的 AI 初创公司 Mistral AI 有些躁动不安。他们将 Le Chat 再一次升级,引入了一些强大的新功能,使其更强大、更直观,也更有趣,在功能上几乎全方位对标 ChatGPT。
来自主题: AI资讯
10051 点击 2025-07-18 09:14
最近几个月,由谷歌和 Meta 前研究人员建立的欧洲的 AI 初创公司 Mistral AI 有些躁动不安。他们将 Le Chat 再一次升级,引入了一些强大的新功能,使其更强大、更直观,也更有趣,在功能上几乎全方位对标 ChatGPT。

Meta 143亿美元收购Scale AI近一半的股份,竟便宜了其竞争对手!仅在达成协议后的48小时内,多家竞争对手们纷纷表示:泼天的富贵来了!「我们的服务器都快爆了!」

这次是真真真挖到OpenAI大动脉了。 Jason Wei,思维链的提出者、o1系列模型的关键人物,被曝也被扎克伯格请走,即将入职Meta。
从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?

快把硅谷大厂挖成筛子的小扎,终于站出来正面回应了:大把研究人员因为天价薪资被打动来了Meta?这个说法基本不对哦,lol~ 他们加入Meta,并非贪图金钱,而是为了造神——build god。
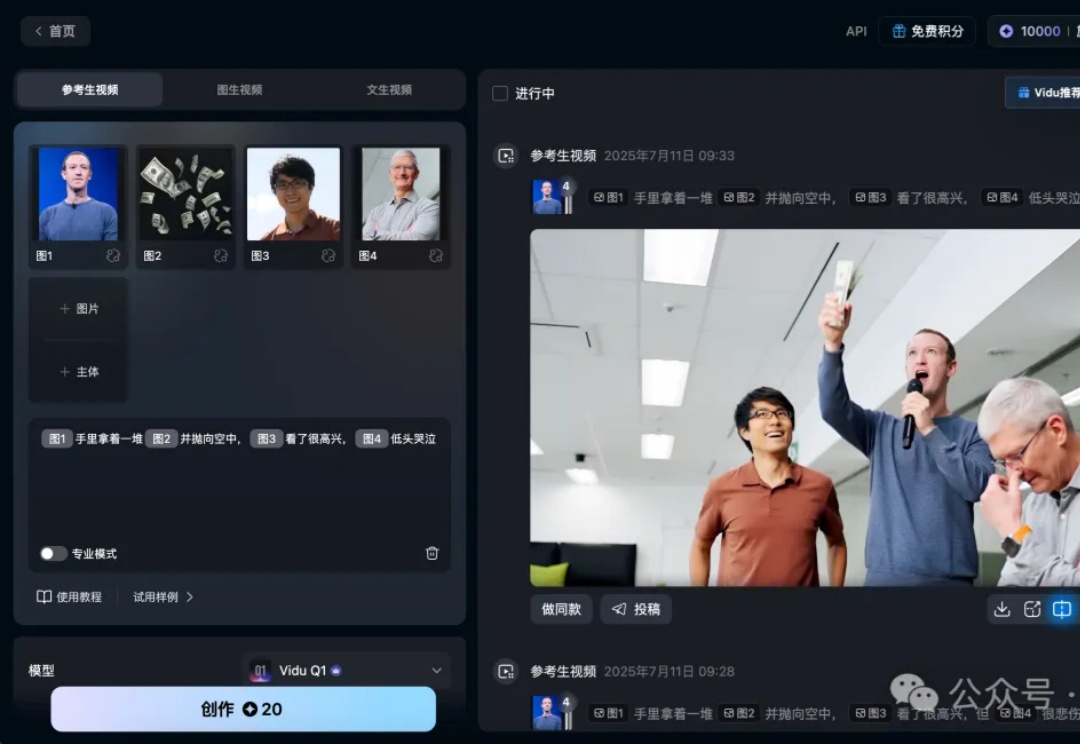
不再是你以为的AI视频生成,国产AI已经开启下一个Level了。

智能眼镜配镜对视力受损用户如近视者存在障碍。分析小米、雷鸟、Ray-Ban Meta等品牌流程,显示第一方服务不便、价格高且支持有限,第三方配镜可行但面临反射问题或调节局限。强调全球22亿视力受损人群需普惠适配方案,否则智能眼镜无法普及。
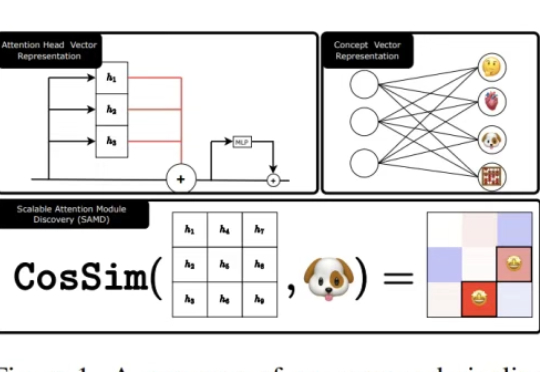
AI也能选择性失忆?Meta联合NYU发布新作,轻松操控缩放Transformer注意头,让大模型「忘掉狗会叫」。记忆可删、偏见可调、安全可破,掀开大模型「可编辑时代」,安全边界何去何从。

在硅谷,顶尖AI人才的身价突破天际!最近,Meta豪掷数亿美元签下最顶尖的AI研究者。硅谷这场人才战争也越演越烈。这是否值得投资?这场人才争夺背后,又隐藏着怎样的深层次问题?

根据彭博社查阅的内部备忘录,Meta 已完成收购专注于语音技术的小型人工智能初创公司 PlayAI 的交易。