
Meta新突破!跨模态生成告别噪声:流匹配实现任意模态无缝流转
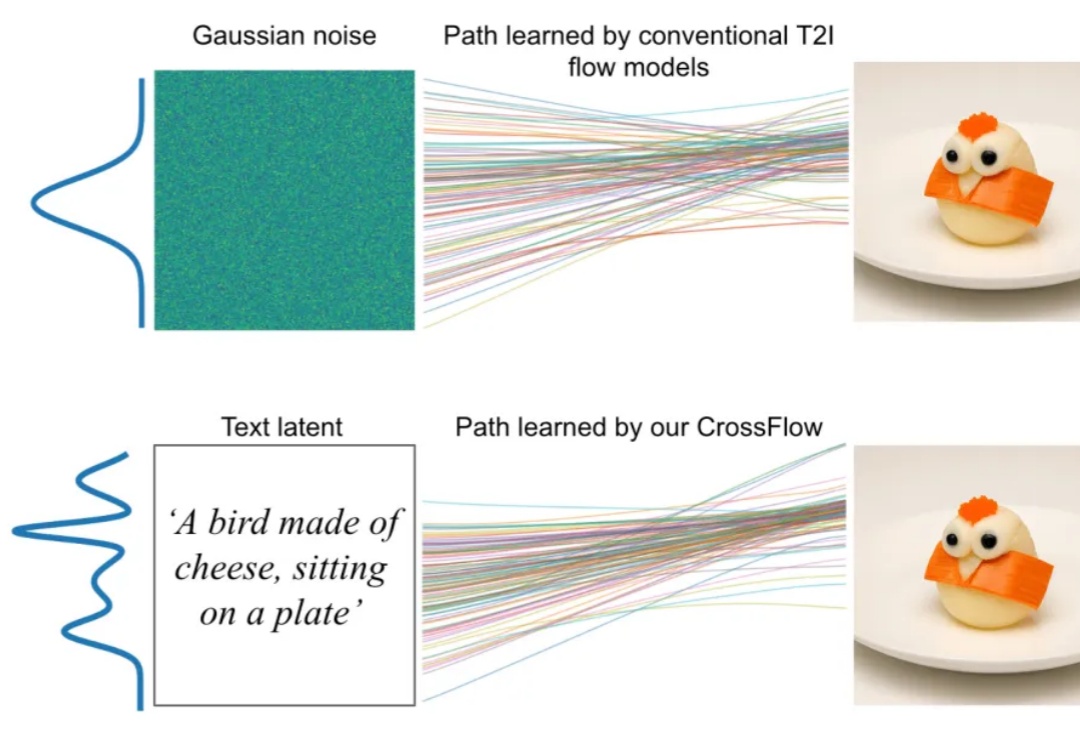
Meta新突破!跨模态生成告别噪声:流匹配实现任意模态无缝流转在人工智能领域,跨模态生成(如文本到图像、图像到文本)一直是技术发展的前沿方向。现有方法如扩散模型(Diffusion Models)和流匹配(Flow Matching)虽取得了显著进展,但仍面临依赖噪声分布、复杂条件机制等挑战。
来自主题: AI技术研报
8659 点击 2025-06-04 14:18
在人工智能领域,跨模态生成(如文本到图像、图像到文本)一直是技术发展的前沿方向。现有方法如扩散模型(Diffusion Models)和流匹配(Flow Matching)虽取得了显著进展,但仍面临依赖噪声分布、复杂条件机制等挑战。
近期,MetaNovas Biotech 元星智药的首席科学家罗衡博士接受了《happi China》杂志的采访。访谈中,他围绕 AI 加生物知识图谱驱动的机制理解和功效型原料开发,深度剖析了 AI 技术,特别是生物知识图谱的引入,如何加速化妆品原料的研发,助力开发更高效、更精准的功效型化妆品……
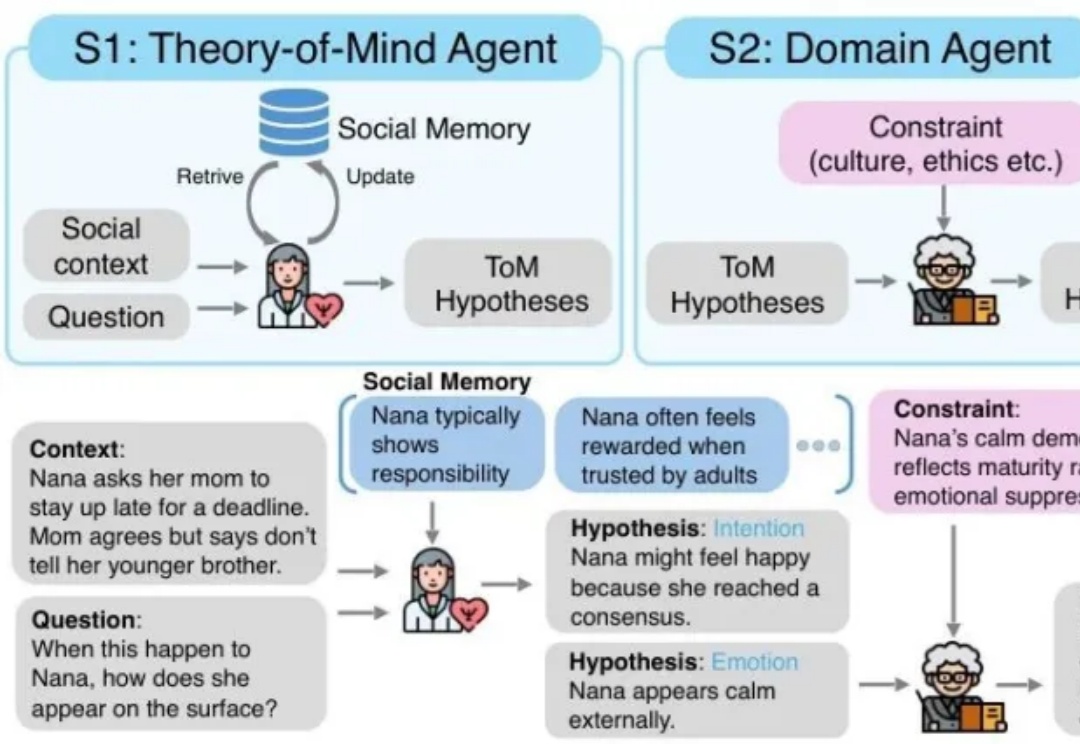
MetaMind是一个多智能体框架,专门解决大语言模型在社交认知方面的根本缺陷。传统的 LLM 常常难以应对现实世界中人际沟通中固有的模糊性和间接性,无法理解未说出口的意图、隐含的情绪或文化敏感线索。MetaMind首次使LLMs在关键心理理论(ToM)任务上达到人类水平表现。

面对谷歌、OpenAI等劲敌猛攻及Llama 4翻车、人才流失困境,小扎决定重组Meta GenAI团队,设AI产品、AGI基础和FAIR三大架构。
从OpenAI 的 4o 到 Stable Diffusion,能够根据文本提示生成逼真图像的 AI 基础模型如今已比比皆是。相比之下,能够仅凭文本提示就生成完整、连贯的 3D 在线环境的基础模型才刚刚崭露头角。

Meta推出KernelLLM,这个基于Llama 3.1微调的8B模型,竟能将PyTorch代码自动转换为高效Triton GPU内核。实测数据显示,它的单次推理性能超越GPT-4o和DeepSeek V3,多次生成时得分飙升。

五天前,一笔震惊科技圈的重磅收购案浮出水面。OpenAI宣布以高达65亿美元的价格,收购了由前苹果首席设计官Jony Ive创办的AI硬件公司io,并计划将其打造为一个专注消费级智能设备的核心部门。

想象一下,你是一位金融分析师,面前堆满了数百页的季报、SEC文件和市场数据,你需要在明天早上交出一份全面的行业分析报告。
不久前,麦炽科技与广大大在北京举办了一场“AI潮涌·文化共生”的行业论坛。Meta 大中华区行业副总经理 David Chen 陈晶在台上做了一场主题为《AI APP出海:产品、流量、合规三大决胜之道》的演讲。陈晶提到了很多Meta的数据,以及各种投放优势。比如,Meta平均每日活跃用户数为34.3亿,是目前全世界日活最高的平台。

AI编程梦被撕碎!最新研究用57.6万个代码样本揭示:超20%代码依赖的是不存在的软件包。苹果、微软都曾中招,而Meta和微软还在高喊「未来AI写95%代码」。AI写代码的神话,正在变成安全灾难。