刚刚,大模型装上「鹰眼」!首创高刷视频理解,谷歌Gemini 2.5完败
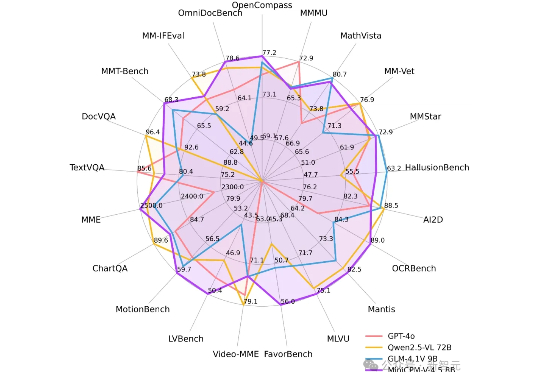
刚刚,大模型装上「鹰眼」!首创高刷视频理解,谷歌Gemini 2.5完败刚刚,面壁智能再放大招——MiniCPM-V 4.5多模态端侧模型横空出世:8B参数,越级反超72B巨无霸,图片、视频、OCR同级全线SOTA!不仅跑得快、看得清,还能真正落地到车机、机器人等。这一次,它不只是升级,而是刷新了端侧AI的高度。
来自主题: AI技术研报
10429 点击 2025-08-27 13:05
 搜索
搜索
刚刚,面壁智能再放大招——MiniCPM-V 4.5多模态端侧模型横空出世:8B参数,越级反超72B巨无霸,图片、视频、OCR同级全线SOTA!不仅跑得快、看得清,还能真正落地到车机、机器人等。这一次,它不只是升级,而是刷新了端侧AI的高度。

今天,我们正式开源 8B 参数的面壁小钢炮 MiniCPM-V 4.5 多模态旗舰模型,成为行业首个具备“高刷”视频理解能力的多模态模型,看得准、看得快,看得长!高刷视频理解、长视频理解、OCR、文档解析能力同级 SOTA,且性能超过 Qwen2.5-VL 72B,堪称最强端侧多模态模型。
7 月 1 日,国际顶级学术期刊《Nature》旗下子刊《Nature Communications》正式刊登了来自清华、面壁等研究团队联合研发的高效端侧多模态大模型MiniCPM-V 核心研究成果。

本文深入剖析 MiniCPM4 采用的稀疏注意力结构 InfLLM v2。作为新一代基于 Transformer 架构的语言模型,MiniCPM4 在处理长序列时展现出令人瞩目的效率提升。传统Transformer的稠密注意力机制在面对长上下文时面临着计算开销迅速上升的趋势,这在实际应用中造成了难以逾越的性能瓶颈。

有史以来最具想象力的小钢炮系列,MiniCPM 4.0 来了!
不知道还有多少人记得那场发布会。

又一个国产AI在外网被刷屏了!这个AI,正是来自面壁智能最新的模型——MiniCPM-o 2.6。
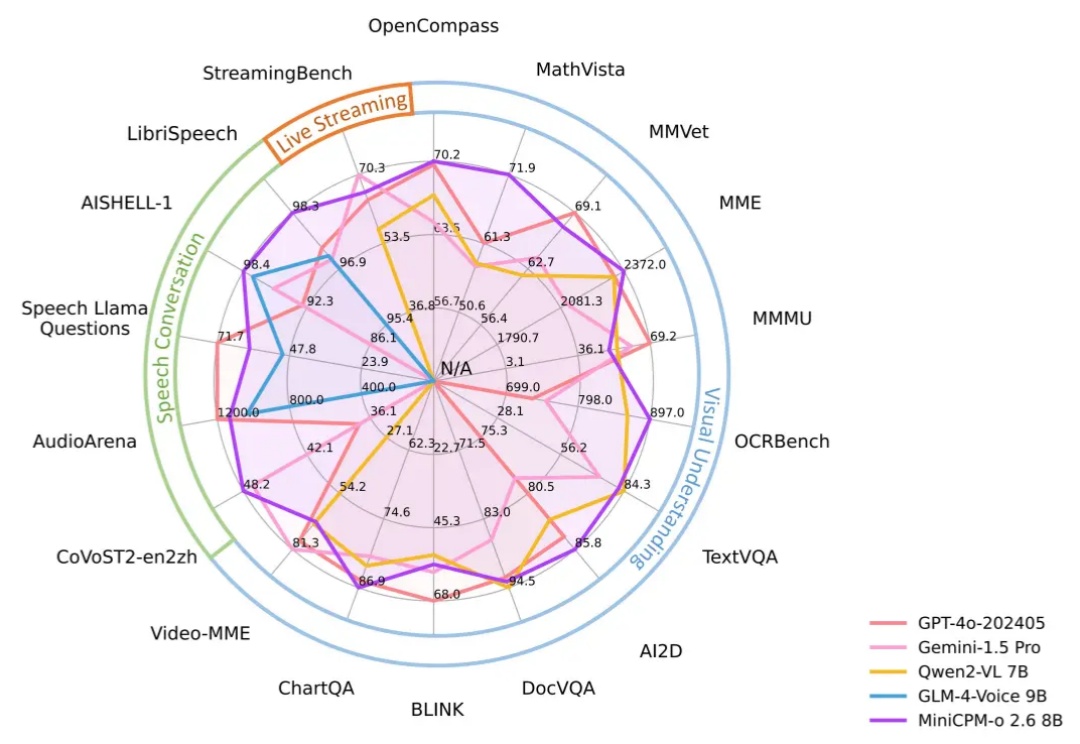
昨天,面壁低调(没媒体曝光)发布了 新模型 MiniCPM-o 2.6:【开源】【端侧】比肩 GPT-4o,只有 8B,非常强!

大模型的记忆限制被打破了,变相实现“无限长”上下文。最新成果,来自清华、厦大等联合提出的LLMxMapReduce长本文分帧处理技术。

你敢相信 4B 参数小模型,性能却超越千亿量级的 GPT-3.5 !OpenAI、谷歌、微软、苹果等一众海内外巨头还没做到的事,被一家中国大模型公司抢先了!