vivo突破手机AI部署难题,绕开MoE架构限制,骁龙8 Elite流畅运行|ICCV 2025
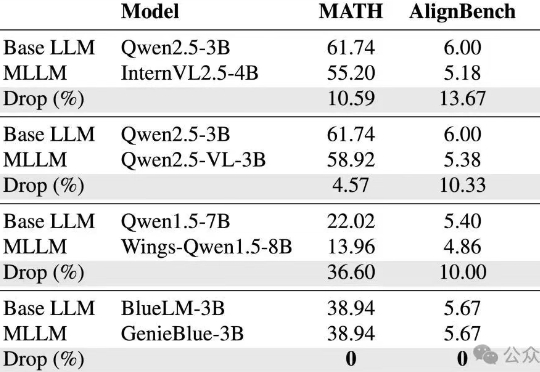
vivo突破手机AI部署难题,绕开MoE架构限制,骁龙8 Elite流畅运行|ICCV 2025vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。
来自主题: AI技术研报
8654 点击 2025-07-05 13:12