
RL新思路!复旦用游戏增强VLM通用推理,性能匹敌几何数据
RL新思路!复旦用游戏增强VLM通用推理,性能匹敌几何数据复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。
来自主题: AI技术研报
9645 点击 2025-10-21 10:05
 搜索
搜索
复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。
近日,来自 MetaGPT、蒙特利尔大学和 Mila 研究所、麦吉尔大学、耶鲁大学等机构的研究团队发布 CARE 框架,一个新颖的原生检索增强推理框架,教会 LLM 将推理过程中的上下文事实与模型自身的检索能力有机结合起来。该框架现已全面开源,包括训练数据集、训练代码、模型 checkpoints 和评估代码,为社区提供一套完整的、可复现工作。

全新一代 video-SALMONN 2/2+、首个开源推理增强型音视频理解大模型 video-SALMONN-o1(ICML 2025)、首个高帧率视频理解大模型 F-16(ICML 2025),以及无文本泄漏基准测试 AVUT(EMNLP 2025) 正式发布。新阵容在视频理解能力与评测体系全线突破,全面巩固 SALMONN 家族在开源音视频理解大模型赛道的领先地位。
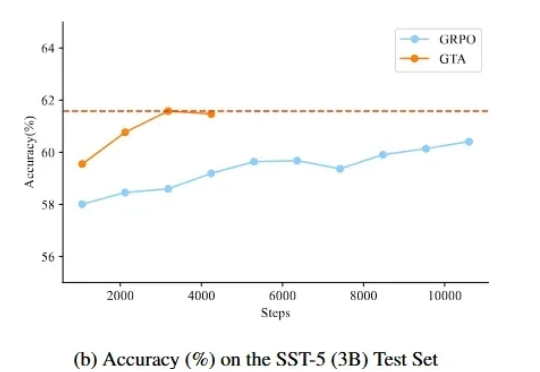
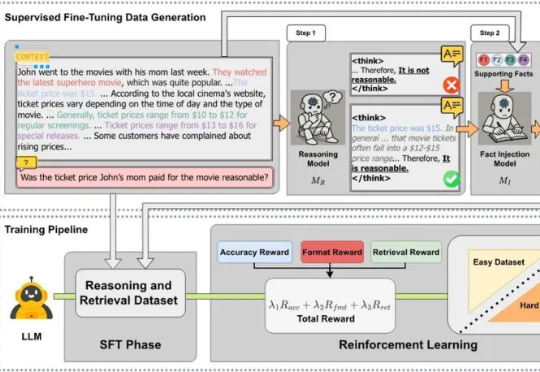
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
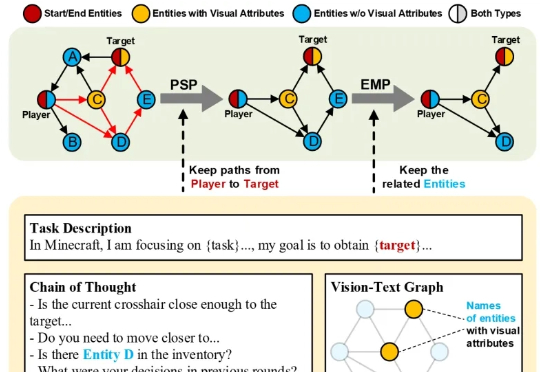
在大多数人眼中,《我的世界》(Minecraft)只是一款自由度极高的沙盒游戏。 而在香港科技大学(广州)与腾讯联合团队的眼中,它却是一座可以演练通用人工智能的“数字练兵场”。
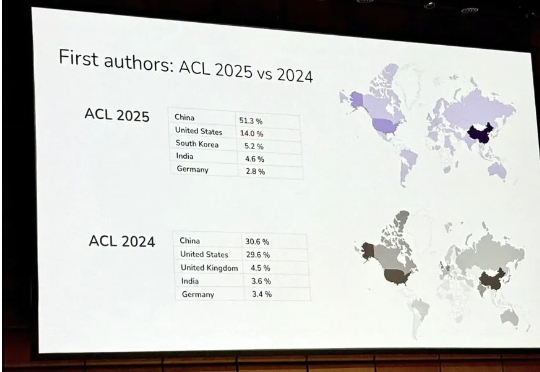
ACL 是计算语言学和自然语言处理领域的顶级国际会议,由国际计算语言学协会组织,每年举办一次。一直以来,ACL 在 NLP 领域的学术影响力都位列第一,它也是 CCF-A 类推荐会议。今年的 ACL 大会已是第 63 届,于 2025 年 7 月 27 日至 8 月 1 日在奥地利维也纳举行。
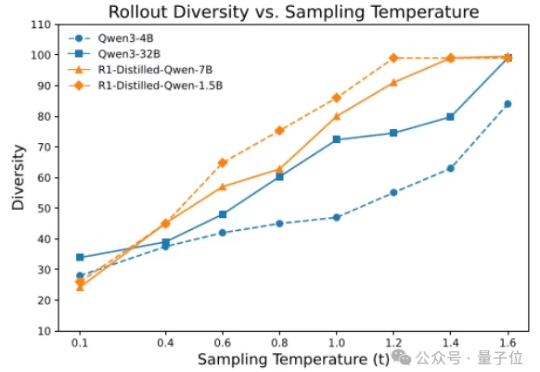
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。
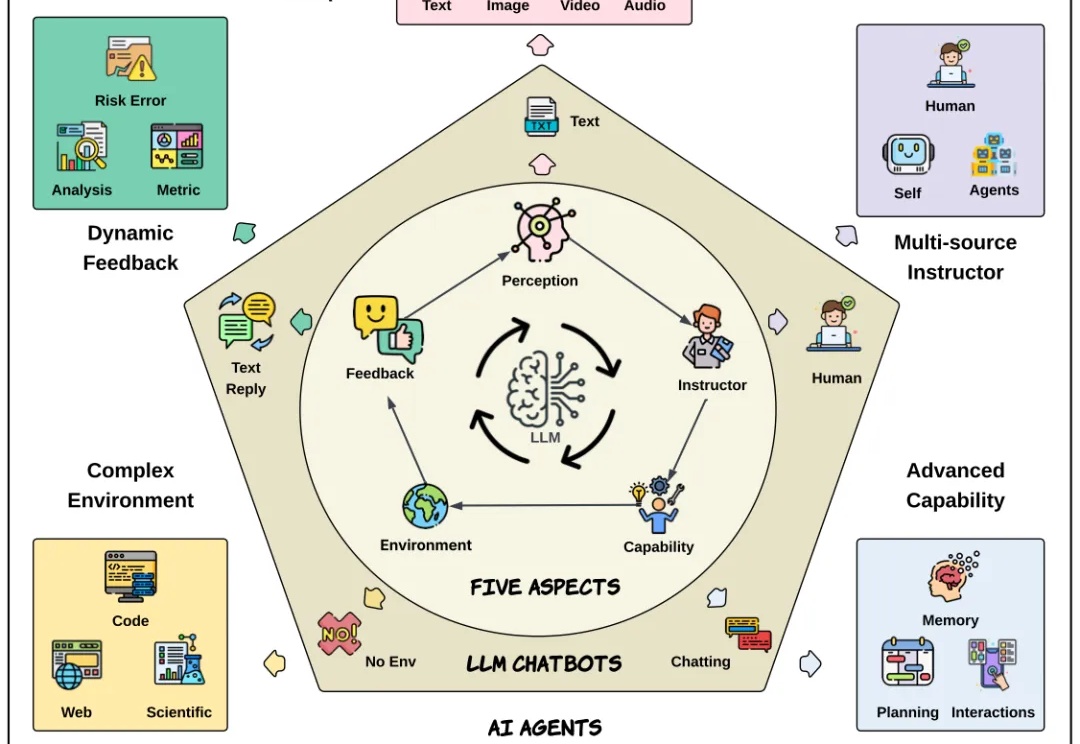
自从 Transformer 问世,NLP 领域发生了颠覆性变化。大语言模型极大提升了文本理解与生成能力,成为现代 AI 系统的基础。而今,AI 正不断向前,具备自主决策和复杂交互能力的新一代 AI Agent 也正加速崛起。
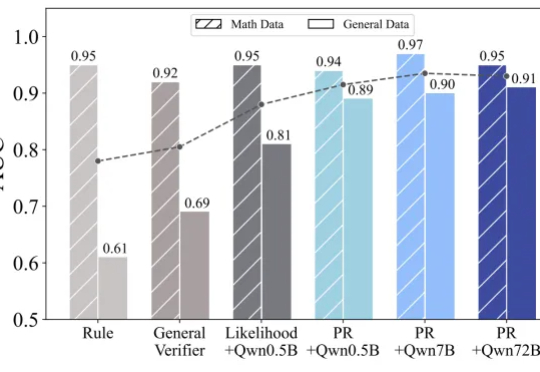
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward

年仅19岁少年,自称破解了谷歌最快的语言模型Gemini Diffusion,引爆社交平台。真相扑朔迷离,但有一点毫无疑问:谷歌I/O大会的「黑马」,比GPT快10倍的速度、媲美人类程序员的代码能力,正在掀起一场NLP范式大洗牌。