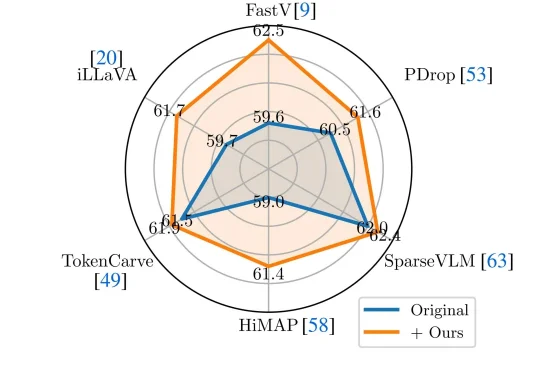
VLM剪枝新SOTA:无需重训练,注意力去偏置超越6大主流方案
VLM剪枝新SOTA:无需重训练,注意力去偏置超越6大主流方案近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。
来自主题: AI技术研报
6823 点击 2026-01-31 12:30
 搜索
搜索
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。
好家伙,AGI真的「Open」了我的生活。(doge)

世界模型迎来高光时刻:谷歌还在闭源,中国团队已经把SOTA级世界模型全面开源了,LingBot-World正面硬刚Genie 3,彻底打破了全球垄断!
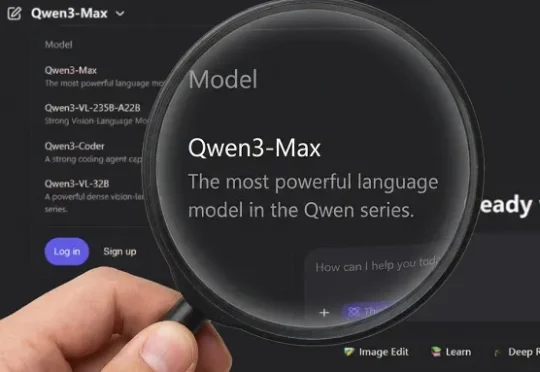
阿里巴巴推出了Qwen3-Max-Thinking,这是阿里千问系列目前能力最强的旗舰级推理模型,在19项权威基准测试中,Qwen3-Max-Thinking跟GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等顶尖模型打得有来有回,搭配测试时扩展(TTS)能力后,能在不少基准测试上达到SOTA。

斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。

比如 2025 年新推出的 Botanic Atlas 项目,这是个交互式的世界植物地图,收录了超过 3 万种植物的标本,我们可以在地图上看到它们分布在哪儿,还能了解相关知识。

谷歌 DeepMind 发布 D4RT,彻底颠覆了动态 4D 重建范式。它抛弃了复杂的传统流水线,用一个统一的「时空查询」接口,同时搞定全像素追踪、深度估计与相机位姿。不仅精度屠榜,速度更比现有 SOTA 快出 300 倍。这是具身智能与自动驾驶以及 AR 的新基石,AI 终于能像人类一样,实时看懂这个流动的世界。
不讲武德!游戏圈这回真是被AI抄家了。(doge)
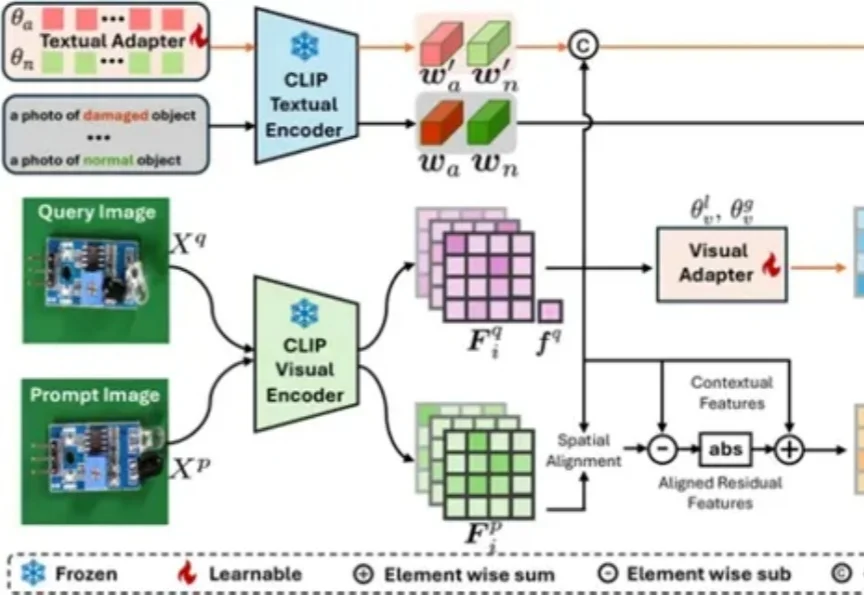
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。

马斯克脑机第一人自曝,不用开颅大脑也能「在线升级」,一个版本迭代即可修复bug,堪比特斯拉OTA。如今,奥特曼也入局了。