
比 JSON 省一半钱的格式,为什么大厂不敢用?
比 JSON 省一半钱的格式,为什么大厂不敢用?最近在研究 RAG 系统优化的时候,发现了一个有意思的格式叫 TOON。全称是 Token-Oriented Object Notation,翻译过来就是面向 Token 的对象表示法。
来自主题: AI技术研报
9598 点击 2026-01-03 14:02
 搜索
搜索
最近在研究 RAG 系统优化的时候,发现了一个有意思的格式叫 TOON。全称是 Token-Oriented Object Notation,翻译过来就是面向 Token 的对象表示法。
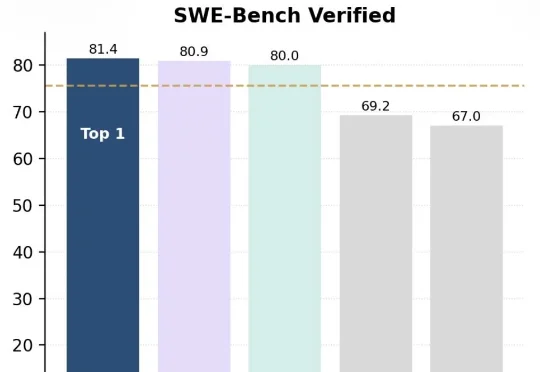
又一个中国新模型被推到聚光灯下,刷屏国内外科技圈。IQuest-Coder-V1模型系列,看起来真的很牛。在最新版SWE-Bench Verified榜单中,40B参数版本的IQuest-Coder取得了81.4%的成绩,这个成绩甚至超过了Claude Opus-4.5和GPT-5.2(这俩模型没有官方资料,但外界普遍猜测参数规模在千亿-万亿级)。

刚刚,由SciMaster团队推出的AI机器学习专家ML-Master 2.0,基于国产开源大模型DeepSeek,在OpenAI权威基准测试MLE-bench中一举击败Google、Meta、微软等国际顶流,刷新全球SOTA,再次登顶!目前该功能已在SciMaster线上平台开放waiting list,欢迎申请体验。

视频生成模型总是「记性不好」?生成几秒钟后物体就变形、背景就穿帮?北大、中大等机构联合发布EgoLCD,借鉴人类「长短时记忆」机制,首创稀疏KV缓存+LoRA动态适应架构,彻底解决长视频「内容漂移」难题,在EgoVid-5M基准上刷新SOTA!让AI像人一样拥有连贯的第一人称视角记忆。

MiniMax最新旗舰级Coding & Agent模型M2.1,刚刚对外发布了。这一次,它直接甩出了一份硬核成绩单,在衡量多语言软件工程能力的Multi-SWE-bench榜单中,以仅10B的激活参数拿下了49.4%的成绩,超越了Claude Sonnet 4.5等国际顶尖竞品,拿下全球SOTA。
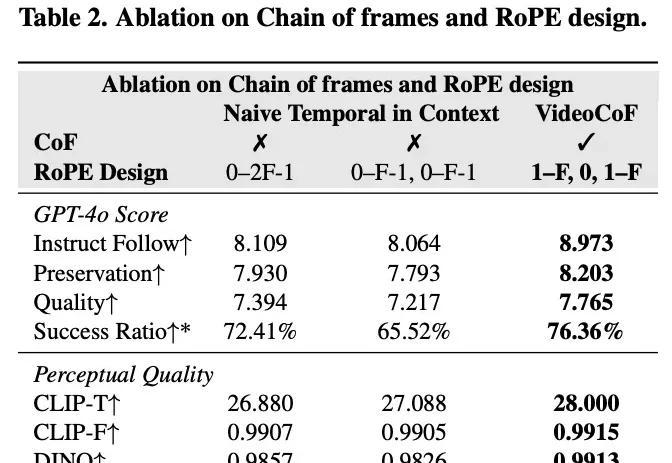
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!

2025倒计时,新SOTA模型涌现没有放缓迹象。一夜之间,编程SOTA模型易主,而且上线即开源,依然来自中国大模型公司——智谱AI,GLM-4.7。

中山大学等机构推出SpatialDreamer,通过主动心理想象和空间推理,显著提升了复杂空间任务的性能。模拟人类主动探索、想象和推理的过程,解决了现有模型在视角变换等任务中的局限,为人工智能的空间智能发展开辟了新路径。

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。

谷歌这波像开了「大小号双修」:前脚用Gemini把大模型战场搅翻,后脚甩出两位端侧「师兄弟」:一个走复古硬核架构回归,一个专职教AI「别光会聊,赶紧去干活」。手机里的智能体中枢,要开始卷起来了。