
推理之父走了!OpenAI七年元老离职:有些研究这里没法做
推理之父走了!OpenAI七年元老离职:有些研究这里没法做新年第一弹,OpenAI研发副总裁Jerry Tworek官宣离职,这位七年老兵给出的理由让人细思恐极:想做在OpenAI做不了的研究。从Dario Amodei出走创立Anthropic,到Ilya政变后离开,再到安全团队负责人摔门而出——OpenAI的核心大脑们正在以惊人的速度流失。
来自主题: AI资讯
10292 点击 2026-01-06 16:49
 搜索
搜索
新年第一弹,OpenAI研发副总裁Jerry Tworek官宣离职,这位七年老兵给出的理由让人细思恐极:想做在OpenAI做不了的研究。从Dario Amodei出走创立Anthropic,到Ilya政变后离开,再到安全团队负责人摔门而出——OpenAI的核心大脑们正在以惊人的速度流失。

AMD公布未来两年芯片路线图。

在 Anthropic 成立五周年前夕,联合创始人兼总裁 Daniela Amodei 罕见接受了公开采访!
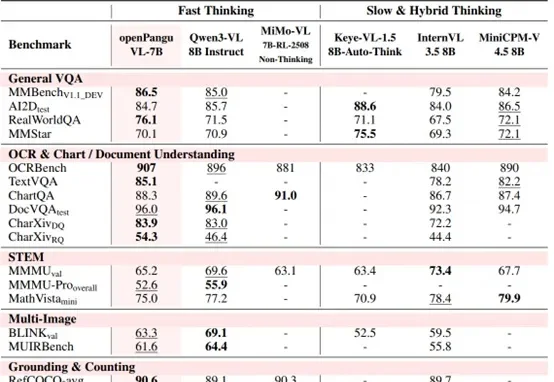
7B量级模型,向来是端侧部署与个人开发者的心头好。

OpenAI推出的第一款AI硬件,产品形态完全超出了这段时间大家的猜测。
在大公司一路高歌猛进的 AI 浪潮里,小创业者和高校研究者正变得越来越迷茫。就连前段时间谷歌创始人谢尔盖・布林回斯坦福,都要回答「大学该何去何从」「从学术到产业的传统路径是否依然重要」这类问题。

AI人才竞争白热化,大厂纷纷高薪招募实习生。Anthropic、OpenAI、Google、Meta使用钞能力,给实习生最高开出12.8万月薪!

竞争是好事,它会逼着我们变得更好。面对竞争的加剧,OpenAI通过快速迭代和新产品发布来强化自身优势,并“确保我们能在这个领域赢下来”。

中国顶级模型全面崛起,Llama迷失,OpenAI失去领先地位。
2026年开局,Anthropic未发一弹已占先机!谷歌首席工程师Jaana Dogan连发多帖,高度赞扬Claude Opus 4.5——没有图像/音频模型、巨大的上下文,仅有一款专注编码的Claude,Anthropic依旧是OpenAI谷歌最有力竞争者。