
受Fable 5封禁影响,GPT-5.6或将延迟发布!
受Fable 5封禁影响,GPT-5.6或将延迟发布!Fable 5被禁用,美国政府指Anthropic态度敷衍,Anthropic坚称是孤立事件。Dario把技术比作核弹,如今却因不愿关闭系统而陷入绝境,把美国整个AI行业拉下水。
来自主题: AI资讯
6631 点击 2026-06-16 10:22
 搜索
搜索
Fable 5被禁用,美国政府指Anthropic态度敷衍,Anthropic坚称是孤立事件。Dario把技术比作核弹,如今却因不愿关闭系统而陷入绝境,把美国整个AI行业拉下水。

法国初创公司 Mistral AI 正洽谈融资约 30 亿欧元(合 35 亿美元),估值约 200 亿欧元,据知情人士透露,这为欧洲人工智能领军企业提供了资金注入,使其在与美国和中国竞争对手的昂贵计算竞赛中保持竞争力。
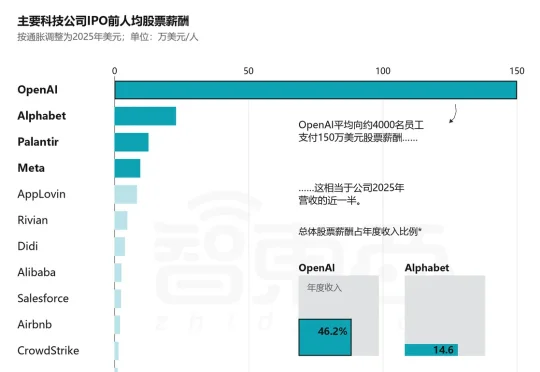
据外媒The Information昨日报道,过去5年间,OpenAI和Anthropic的早期员工及投资者已通过私下股份出售合计套现约140亿美元(约合人民币950亿元)。这一轮员工造富潮正值AI行业IPO竞赛全面升温。6月12日,SpaceX以1.75万亿美元估值登陆纳斯达克,成为这波超级IPO潮中第一个落地的案例。而在此之前,SpaceX至少已连续5年安排员工减持。

都以为OpenAI上市只差临门一脚,纽约州等多州总检察长偏在这节骨眼集体递上传票。

Minerva 正式公开上线了他们的 AI 营销平台,同时宣布完成了这轮融资。投资方名单相当亮眼:The General Partnership、8VC、Lingotto Innovation、Topology Ventures,还有 NBA 官方投资部门 NBA Investments。与此同时,他们还公布了与 OpenAI 的深度合作关系,

主打高端直播 / 会议高清摄像头的Opal Camera在卖了超 5 万台设备后2025 年正式更名 Opal Electronics(以下简称Opal ),转型全品类 AI 消费硬件。随后OpenAI 领投4000 万美元,投资方含三星、Peter Thiel 基金、MKBHD(知名数码博主),投后估值2.75 亿美元。

本周「十字路口」,我们聊 FDE 这个正在被重新定义的岗位与分工:它究竟是在把“售前/交付”换个名字,还是代表 ToB AI 时代新的组织结构与商业边界?当模型越来越强,最后一公里为什么依然最难?企业真正缺的,到底是更强的模型,还是能把 AI 带进流程、接入系统、治理知识、持续迭代并对结果负责的人?
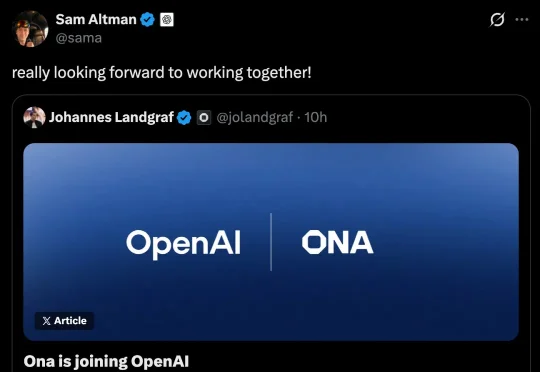
今天,OpenAI正式收购了Ona,一家专注于安全云执行与编排技术的公司。这步棋的战略意义很明显,给Codex补上一块能让AI「下班还在干活」的地基。奥特曼激动表示,「非常期待接下来的合作」。

决策机已推演23万起事件,准确率超90%。
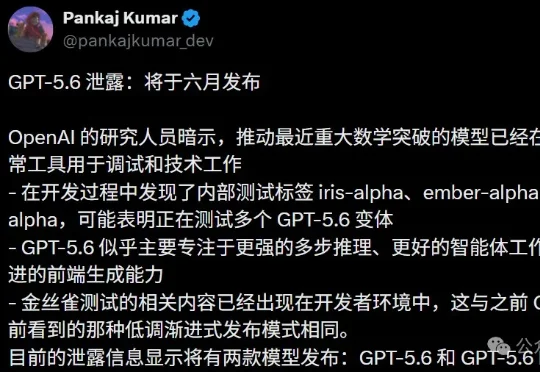
GPT-5.6本月上桌,agentic编码据称已反超Anthropic Mythos!三家旗舰模型撞进同一个6月,两大AI巨头同时冲刺IPO,奥特曼却在内部抛出了一个更大的变量:如果AI先学会自我改进,上市反而不急。