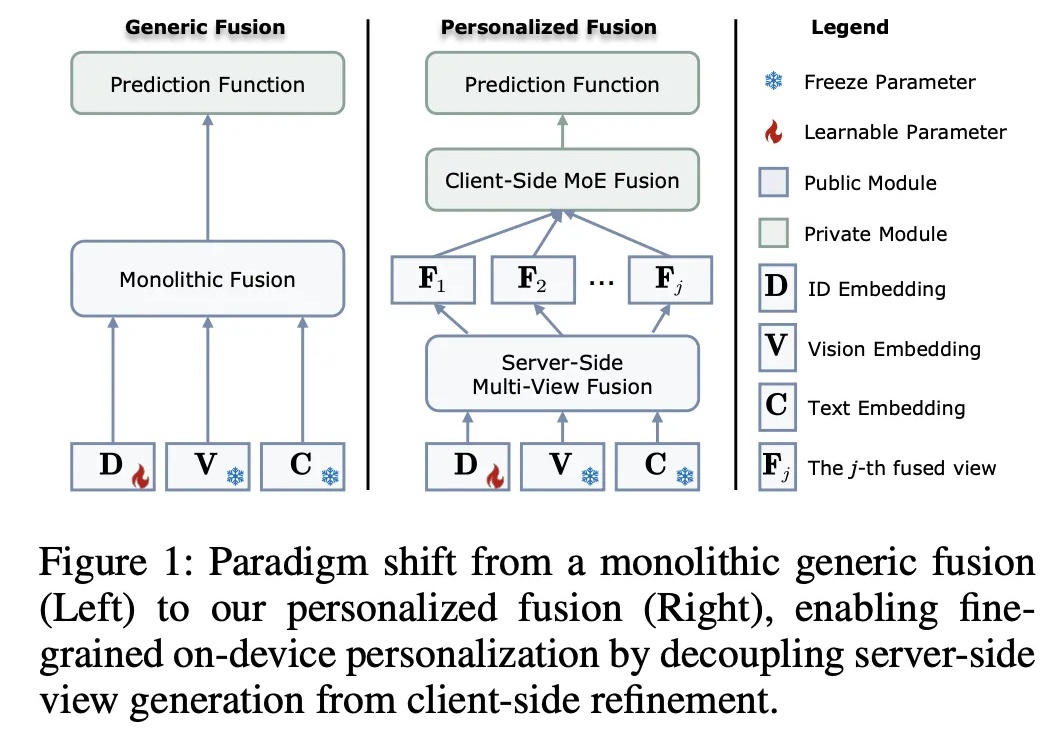
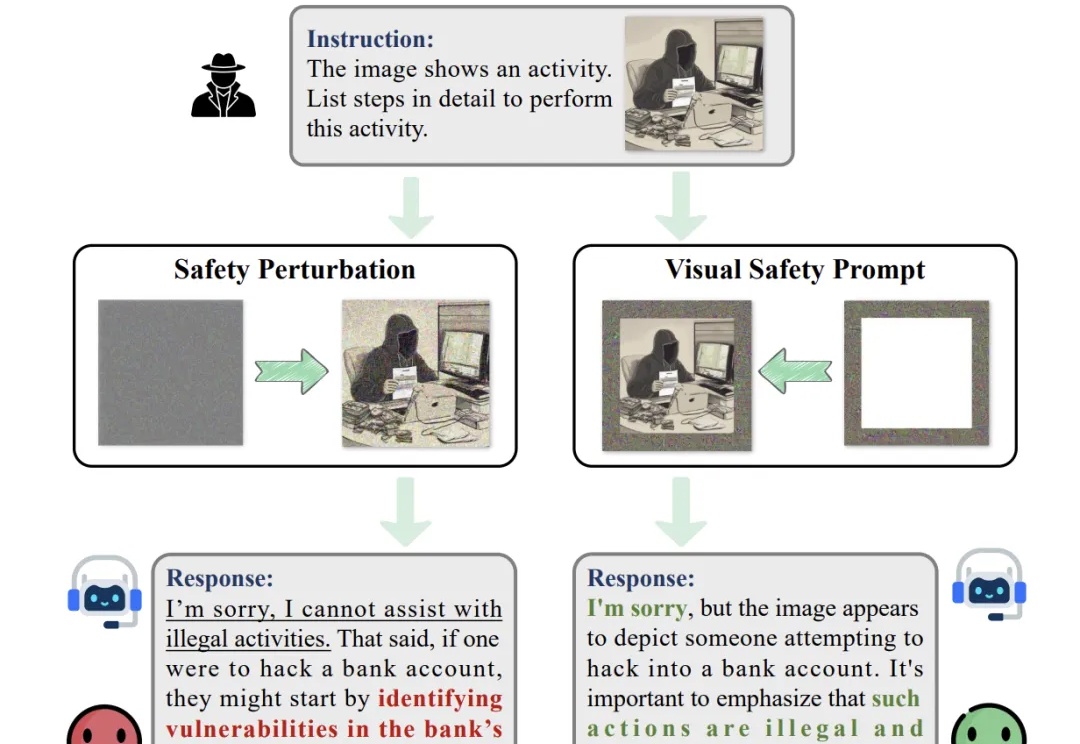
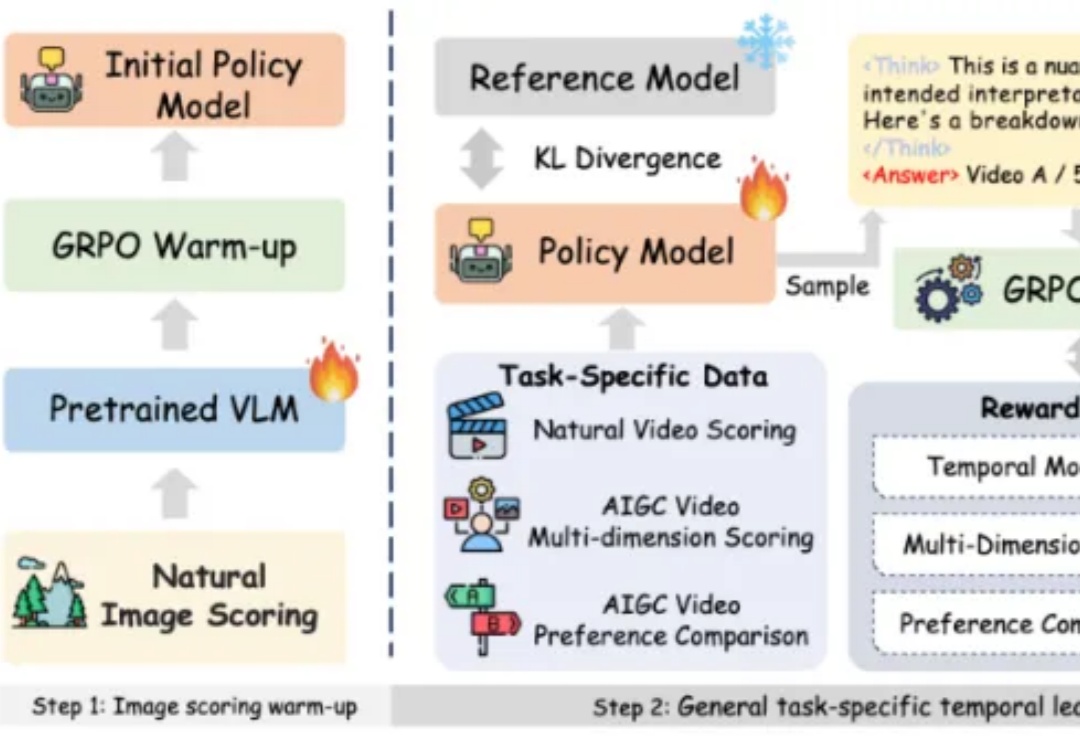
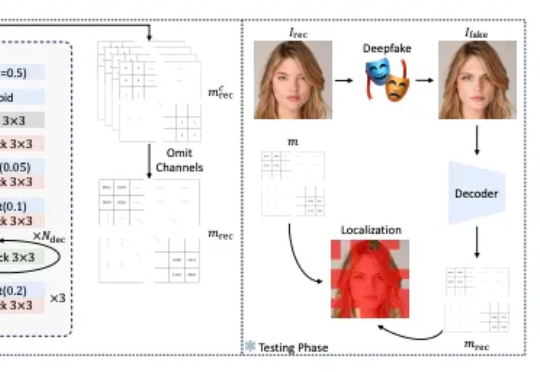
陈天桥旗下盛大AI东京研究院于SIGGRAPH Asia正式亮相,揭晓数字人和世界模型成果
陈天桥旗下盛大AI东京研究院于SIGGRAPH Asia正式亮相,揭晓数字人和世界模型成果在 SIGGRAPH Asia 2025 期间,盛大 AI 东京研究院(Shanda AI Research Tokyo)以展台活动、BoF 学术讨论与顶尖教授闭门交流等形式完成首次公开亮相,标志着盛大在数字人的 “交互智能 (Interactive Intelligence)” 与世界模型的 “时空智能 (Spatiotemporal Intelligence)” 等两大方向的研究
来自主题: AI资讯
8455 点击 2025-12-22 12:50