

MM 2024 Oral: 大模型带你鉴赏世界名画!同济大学发布
MM 2024 Oral: 大模型带你鉴赏世界名画!同济大学发布现有的大模型已经能够创作令人惊叹画作,那鉴赏艺术画作岂不是信手拈来?
来自主题: AI技术研报
6241 点击 2024-08-30 15:05
现有的大模型已经能够创作令人惊叹画作,那鉴赏艺术画作岂不是信手拈来?

在过去的几年中,大型语言模型(Large Language Models, LLMs)在自然语言处理(NLP)领域取得了突破性的进展。这些模型不仅能够理解复杂的语境,还能够生成连贯且逻辑严谨的文本。

地球是平的吗? 当然不是。自古希腊数学家毕达哥拉斯首次提出地圆说以来,现代科学技术已经证明了地球是圆形这一事实。 但是,你有没有想过,如果 AI 被误导性信息 “忽悠” 了,会发生什么? 来自清华、上海交大、斯坦福和南洋理工的研究人员在最新的论文中深入探索 LLMs 在虚假信息干扰情况下的表现,他们发现大语言模型在误导信息反复劝说下,非常自信地做出「地球是平的」这一判断。
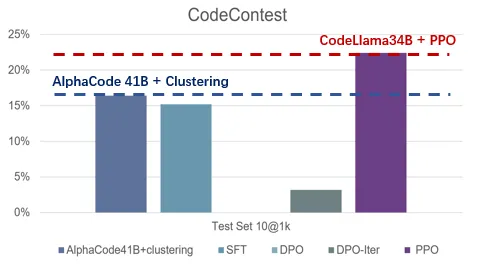
如何让大模型更好的遵从人类指令和意图?如何让大模型有更好的推理能力?如何让大模型避免幻觉?能否解决这些问题,是让大模型真正广泛可用,甚至实现超级智能(Super Intelligence)最为关键的技术挑战。这些最困难的挑战也是吴翼团队长期以来的研究重点,大模型对齐技术(Alignment)所要攻克的难题。

最近,新加坡国立大学联合南洋理工大学和哈工深的研究人员共同提出了一个全新的视频推理框架,这也是首次大模型推理社区提出的面向视频的思维链框架(Video-of-Thought, VoT)。视频思维链VoT让视频多模态大语言模型在复杂视频的理解和推理性能上大幅提升。该工作已被ICML 2024录用为Oral paper。

在现实世界的机器学习应用中,随时间变化的分布偏移是常见的问题。这种情况被构建为时变域泛化(EDG),目标是通过学习跨领域的潜在演变模式,并利用这些模式,使模型能够在时间变化系统中对未见目标域进行良好的泛化。然而,由于 EDG 数据集中时间戳的数量有限,现有方法在捕获演变动态和避免对稀疏时间戳的过拟合方面遇到了挑战,这限制了它们对新任务的泛化和适应性。

怎样才能将可爱又迷人的柯基与柴犬的图像进行区分?

众多神经网络模型中都会有一个有趣的现象:不同的参数值可以得到相同的损失值。这种现象可以通过参数空间对称性来解释,即某些参数的变换不会影响损失函数的结果。基于这一发现,传送算法(teleportation)被设计出来,它利用这些对称变换来加速寻找最优参数的过程。尽管传送算法在实践中表现出了加速优化的潜力,但其背后的确切机制尚不清楚。

在 2024 世界经济论坛的一次会谈中,图灵奖得主 Yann LeCun 提出用来处理视频的模型应该学会在抽象的表征空间中进行预测,而不是具体的像素空间 [1]。借助文本信息的多模态视频表征学习可抽取利于视频理解或内容生成的特征,

鹅妹子嘤!AI硬件,自己也能动手做了!只需一个小时,成本不到八百块。