
DeepSeek,居然只是个副项目?
DeepSeek,居然只是个副项目?你知道吗,DeepSeekTwitter、Mac、Qwen,最初都只是副项目?真正改变世界的产品,可能根本不在公司的PPT路线图上。
来自主题: AI资讯
7628 点击 2025-12-31 15:11
 搜索
搜索
你知道吗,DeepSeekTwitter、Mac、Qwen,最初都只是副项目?真正改变世界的产品,可能根本不在公司的PPT路线图上。
2025最后几天,是时候来看点年度宝藏论文了。
能翻译33语种+5方言,医学术语/粤语翻译实测“能打”。
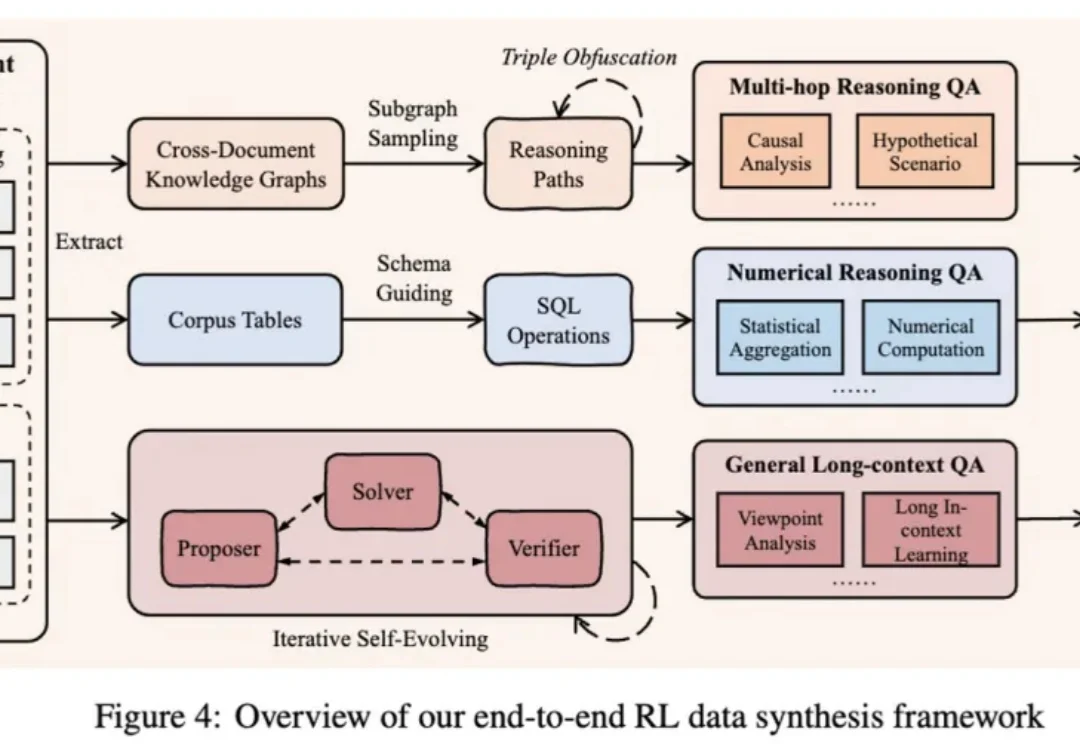
作为大模型从业者或研究员的你,是否也曾为一个模型的 “长文本能力” 而兴奋,却在实际应用中发现它并没有想象中那么智能?
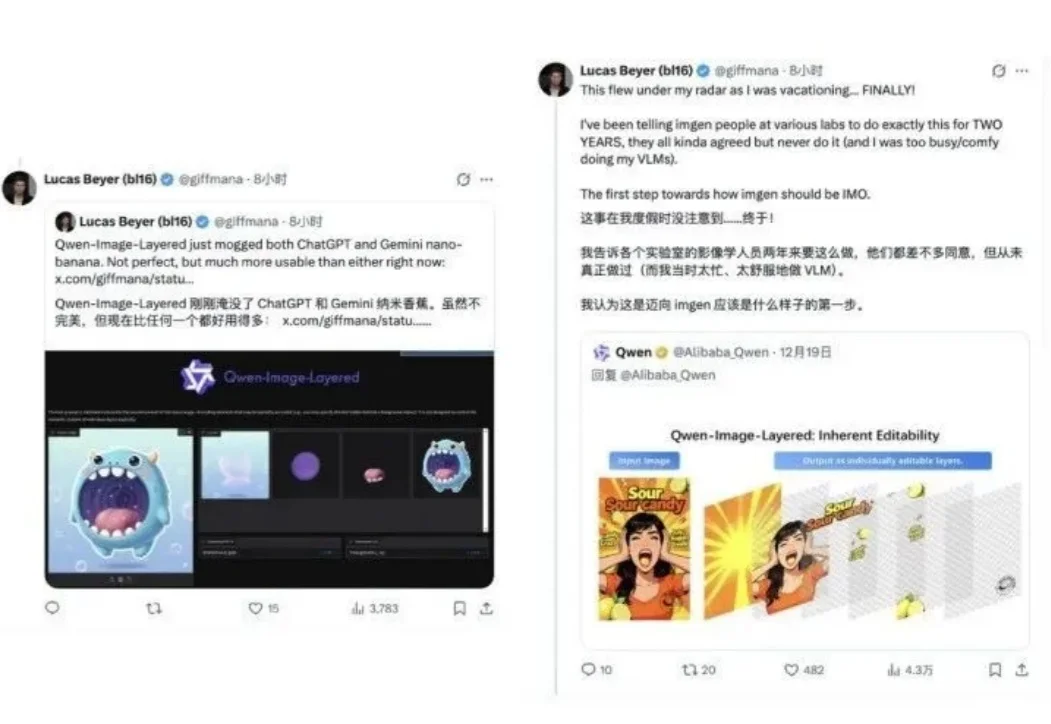
太香了太香了,妥妥完爆ChatGPT和Nano Banana!

热门LoRA首次内置,控光换镜头实测可用。
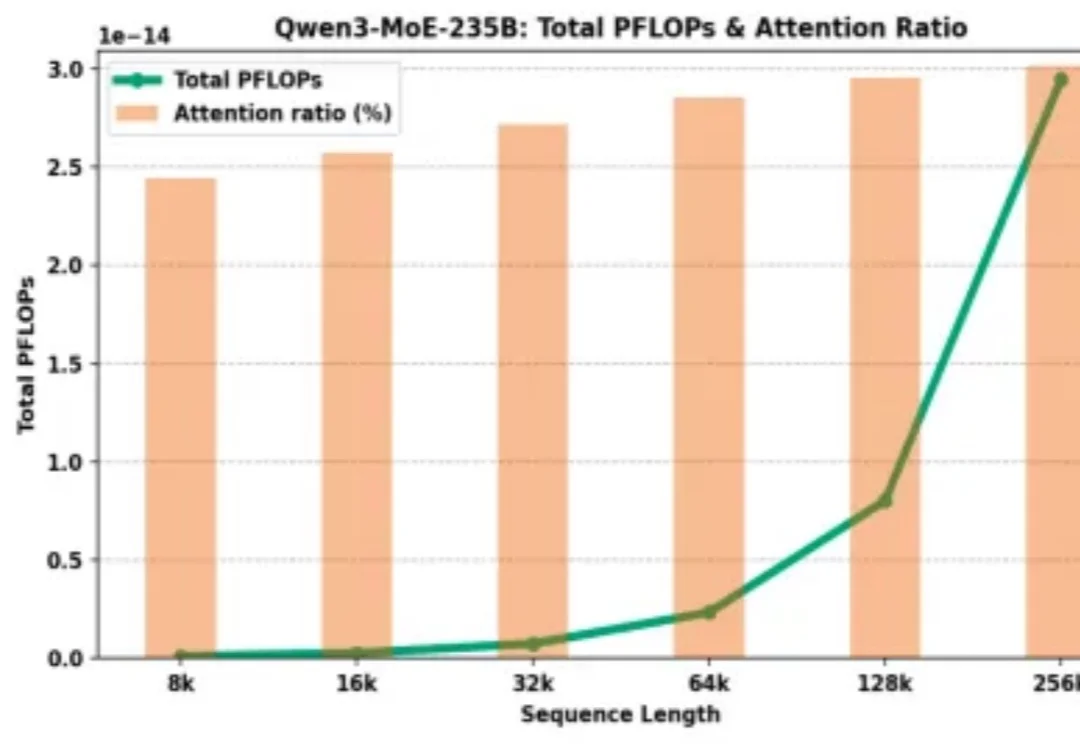
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?

抽奖式的生图体验,确实让很多设计师在尝鲜之后又默默打开了 Photoshop。于是乎,阿里千问团队再次出手,开源了一个叫 Qwen-Image-Layered 的模型,试图从底层逻辑上解决这个问题。

我真栓Q了!围观了场狼人杀,看得我汗流浃背……

AI不仅会做PPT,写代码,它还能理解更深层次的问题。在美国的一项偏重于文化领域的新基准测试中,中国开源模型Qwen3夺冠,DeepSeek的R1跻身前六,力压多家全球顶级的明星模型。