

一招教你解决DeepSeek R1的卡顿问题。
一招教你解决DeepSeek R1的卡顿问题。整个过年,DeepSeek给我用的都卡炸了。 我自己在官方app和网页里,到现在也还是10条回复有8条是“服务器blabla,请稍后重试”。 每次见到这句话,我都想脑溢血。
来自主题: AI资讯
7047 点击 2025-02-05 11:38
整个过年,DeepSeek给我用的都卡炸了。 我自己在官方app和网页里,到现在也还是10条回复有8条是“服务器blabla,请稍后重试”。 每次见到这句话,我都想脑溢血。

DeepSeek千般好,万般好,就是联网搜索还用不了.但先别急,这块拼图也被国产AI搜索玩家用自己的能力补全了: 就在刚刚,秘塔AI搜索宣布融合了DeepSeek-R1满血版。
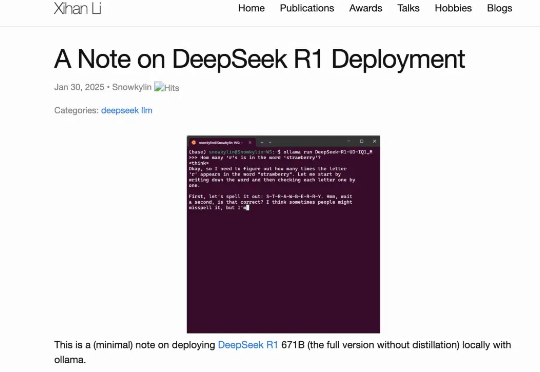
过年这几天,DeepSeek 算是彻底破圈了,火遍大江南北,火到人尽皆知。虽然网络版和 APP 版已经足够好用,但把模型部署到本地,才能真正实现独家定制,让 DeepSeek R1 的深度思考「以你为主,为你所用」。

在这个对谈中,Lex Fridman 与半导体分析专家 Dylan Patel(SemiAnalysis 创始人)和人工智能研究科学家 Nathan Lambert(艾伦人工智能研究所)展开对话,深入探讨 DeepSeek AI 及其开源模型 V3 和 R1,以及由此引发的 AI 发展地缘政治竞争,特别是中美在 AI 芯片和技术出口管制领域的博弈。

奥特曼罕见地承认了自己犯下的「历史错误」,LeCun发文痛批硅谷一大常见病——错位优越感。DeepSeek的终极意义在哪?圈内热转的这篇分析指出,相比R1,R1-Zero具有更重要的研究价值,因为它打破了终极的人类输入瓶颈!

一场改写AI历史的震撼对决正在上演!就在昨天,当DeepSeek R1还在用「降维打击」重构AI格局时,OpenAI王者回归之作o3-mini已悄然降临,用实力证明——王者,从未离场!

国产大模型云服务平台SiliconCloud(硅基流动),首发上线了基于华为云昇腾云服务的DeepSeek-V3、DeepSeek-R1。 DeepSeek-V3:输入只需1块钱/M tokens,输出2块钱/M tokens
春节假期未过半,DeepSeek 掀起的巨浪还在影响着所有和人工智能有关的领域。 今天一觉醒来, DeepSeek R1 模型已经正式加入 Azure AI Foundry 和 GitHub 模型目录,开发人员可以快速地进行实验、迭代,并将这款热门模型集成到他们的工作流程中。
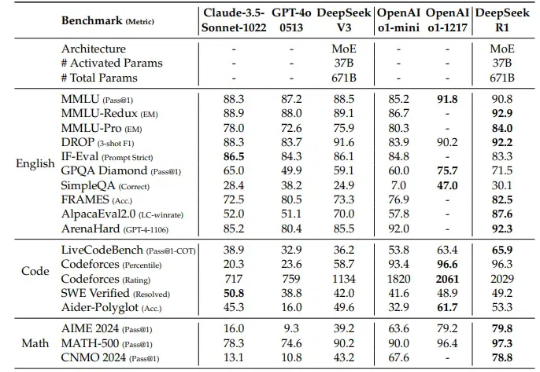
"Deepseek R1不就是一个参数更大的语言模型吗?随便问问题就行了,还需要什么特殊技巧?"——当你说出这句话时,是否意识到自己正像《西游记》里高举紫金葫芦的妖怪,对着齐天大圣叫嚣:"我叫你的名字,你敢答应吗?"

梁文锋带领着DeepSeek,还在继续搅动大模型行业。继用R1模型炸场之后,1月28日凌晨,除夕夜前一晚,DeepSeek又开源了其多模态模型Janus-Pro-7B,宣布在GenEval和DPG-Bench基准测试中击败了DALL-E 3(来自 OpenAI)和Stable Diffusion。