

最懂管钱的AI?这个刚刚发布的金融推理大模型,专业测试超DeepSeek|WAIC2025
最懂管钱的AI?这个刚刚发布的金融推理大模型,专业测试超DeepSeek|WAIC2025在社交平台上,「AI 帮我选基金,结果赚了 8%」、「AI 自动炒股,秒杀巴菲特?」之类的帖子不时刷屏,炒股机器人、对话式理财助手有关的 Agent 也不断涌现。
来自主题: AI资讯
10535 点击 2025-07-28 17:48
在社交平台上,「AI 帮我选基金,结果赚了 8%」、「AI 自动炒股,秒杀巴菲特?」之类的帖子不时刷屏,炒股机器人、对话式理财助手有关的 Agent 也不断涌现。
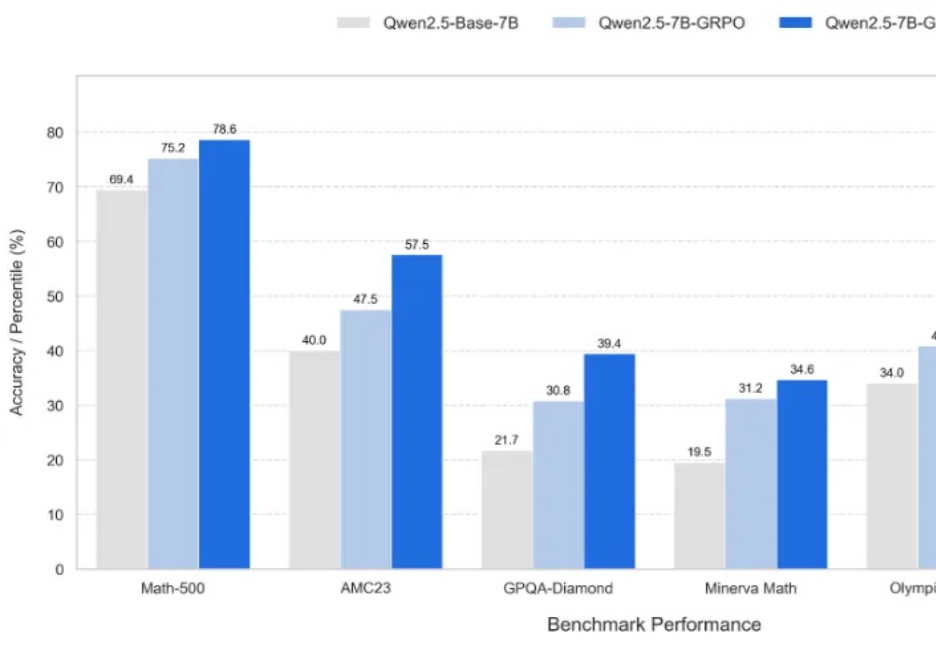
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。
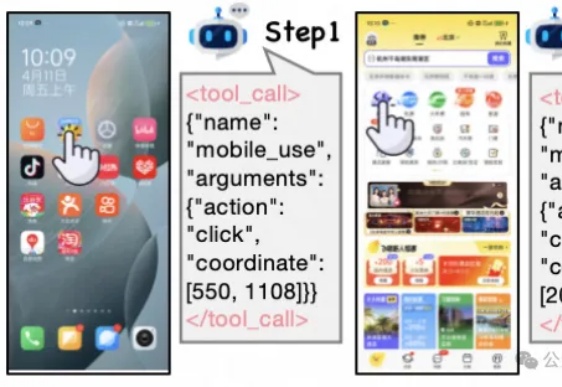
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。

基于Qwen2.5架构,采用DeepSeek-R1-0528生成数据,英伟达推出的OpenReasoning-Nemotron模型,以超强推理能力突破数学、科学、代码任务,在多个基准测试中创下新纪录!数学上,更是超越了o3!
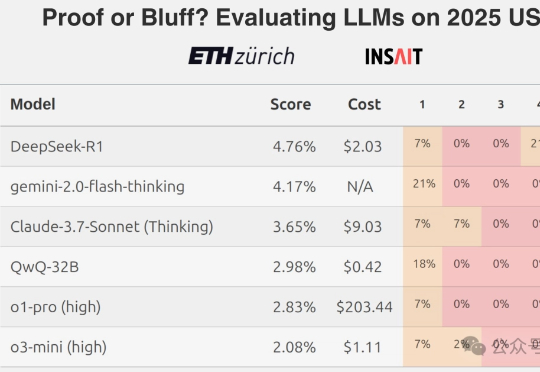
AI做奥数的神话,刚刚被戳破了!最新出炉的2025 IMO数学竞赛中,全球顶尖AI模型无一例外翻车了。即便是冠军Gemini也只拿下可怜的31分,连铜牌都摸不到。Grok-4更是摆烂到底,连DeepSeek-R1都令人失望。看来,AI想挑战人类奥数大神,还为时尚早。

半年前,DeepSeek R1 的推出轰动了全球,无论东西方都是火的一塌糊涂,更是被外网称为 AI 领域的 Sputnik 时刻。
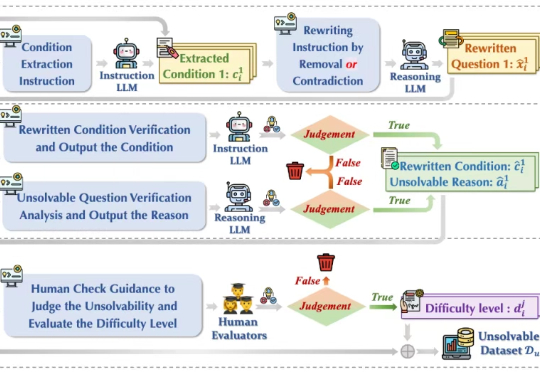
今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。
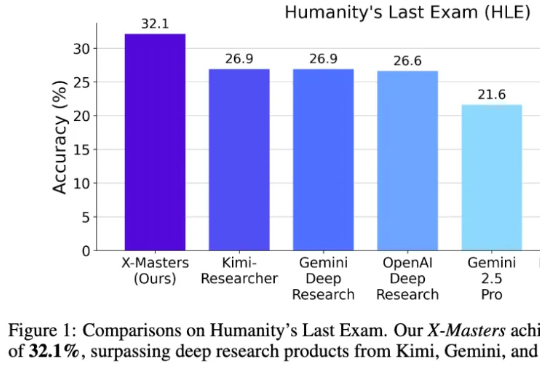
“人类最后的考试”首次突破30分,还是咱国内团队干的! 该测试集是出了名的超难,刚推出时无模型得分能超过10分。
今日,昆仑万维重磅开源多模态推理模型Skywork-R1V 3.0,这是其迄今最强多模态推理模型,参数规模为38B,在多个多模态推理基准测试中取得了开源最佳(SOTA)性能。
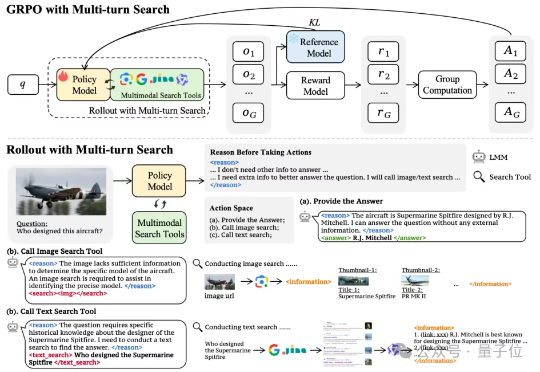
多模态模型学会“按需搜索”!字节&NTU最新研究,优化多模态模型搜索策略——通过搭建网络搜索工具、构建多模态搜索数据集以及涉及简单有效的奖励机制,首次尝试基于端到端强化学习的多模态模型自主搜索训练。