
从好莱坞特效到AI芯片的十年之约:SIGGRAPH Asia 2025登陆香港!
从好莱坞特效到AI芯片的十年之约:SIGGRAPH Asia 2025登陆香港!十年前,我们是国际顶会的仰望者;十年后,SIGGRAPH Asia重返家门,中国已从技术跟跑者变为AI与图形融合新时代的定义者之一,这场盛会不仅是一次技术复盘,更是一次面向全球的实力宣言。
来自主题: AI资讯
11760 点击 2025-11-17 14:34
 搜索
搜索
十年前,我们是国际顶会的仰望者;十年后,SIGGRAPH Asia重返家门,中国已从技术跟跑者变为AI与图形融合新时代的定义者之一,这场盛会不仅是一次技术复盘,更是一次面向全球的实力宣言。
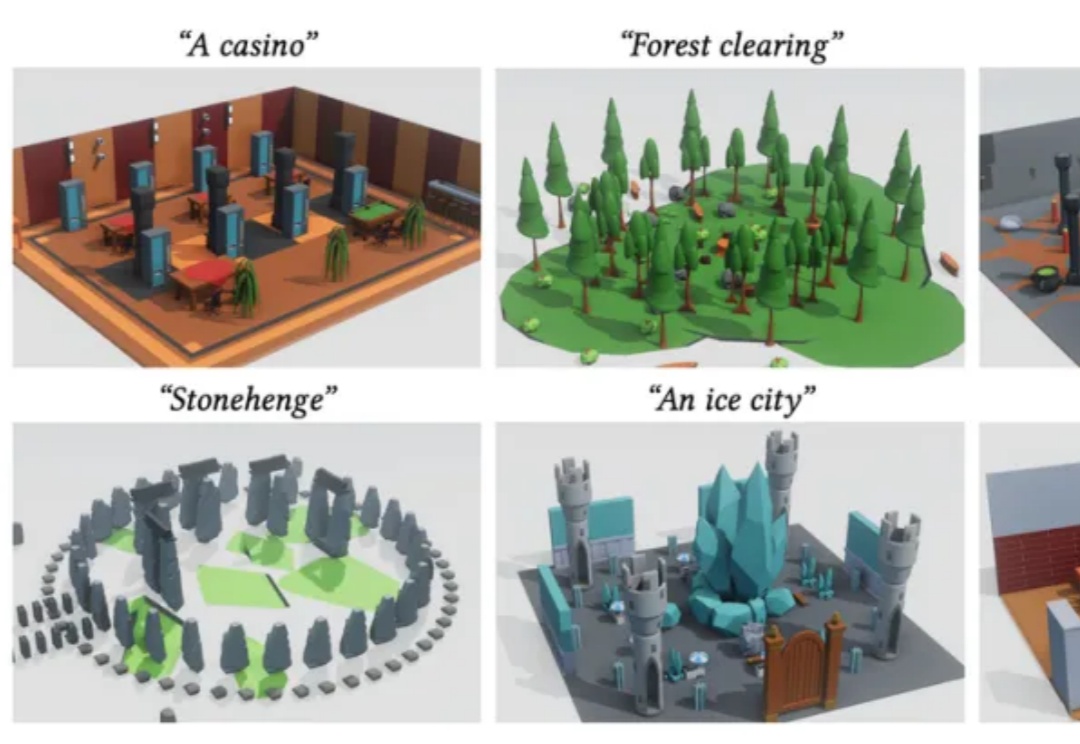
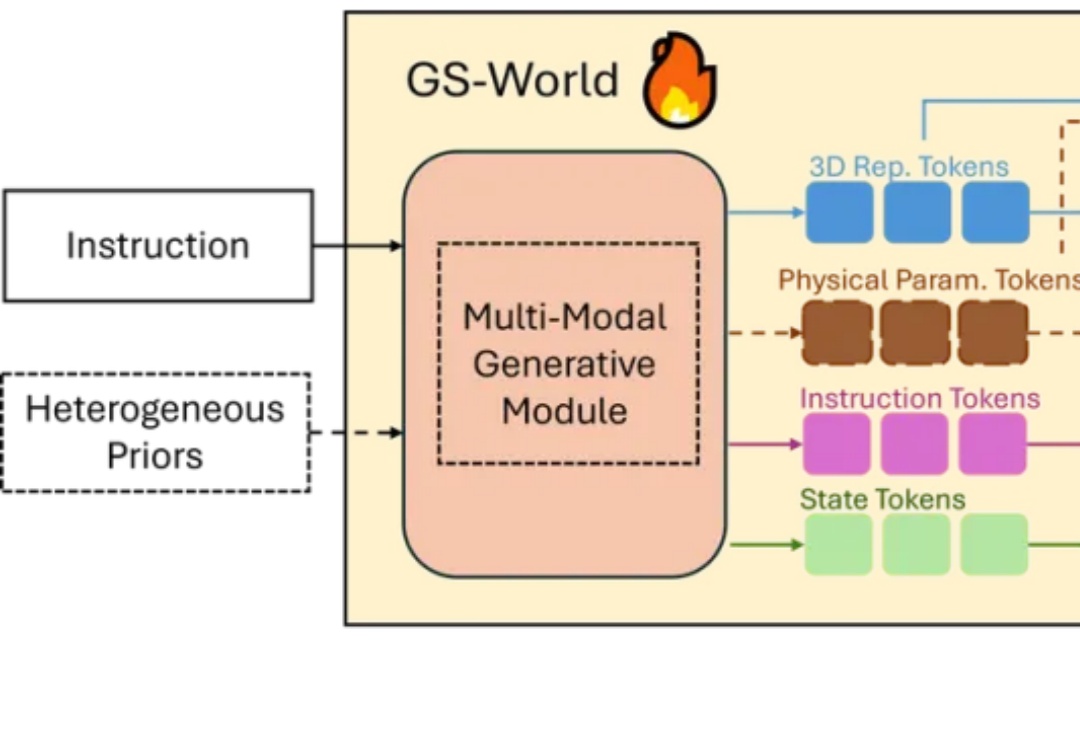
随着生成式 AI 的快速发展,从文本生成图像、视频,到构建完整的三维世界,AI “创造空间” 的能力正以前所未有的速度突破边界。然而,现有 3D 场景生成方法仍存在明显局限:模型往往直接输出每个物体的几何参数(位置、大小、方向等),结果容易出现漂浮、重叠、穿模等问题;场景结构缺乏逻辑一致性,难以编辑或复用,更无法像程序那样精确控制空间关系与生成逻辑。

目前,95 后拉斐尔·凯(Raphael Kay)是一名美国哈佛大学的在读博士生。尽管还是一名学生,但他在 2025 年初依托黏菌在美国创办了一家名为 Mireta 的初创公司,他带领公司将 5 亿年前黏菌的生长规律转化为了城市设计工具,助力于开发更高效、更有弹性的城市网络。
2025 年秋的具身智能赛道正被巨头动态点燃:特斯拉上海超级工厂宣布 Optimus 2.0 量产下线,同步开放开发者平台提供运动控制与环境感知 SDK,试图通过生态共建破解数据孤岛难题;英伟达则在 SIGGRAPH 大会抛出物理 AI 全栈方案,其 Omniverse 平台结合 Cosmos 世界模型可生成高质量合成数据,直指真机数据短缺痛点。

知识图谱推理是人工智能的关键技术,在多领域有广泛应用,但现有方法存在推理效率低、表达能力不足、过平滑问题等挑战。中科大研究团队提出DuetGraph,采用双阶段粗到细推理框架与双通路全局 - 局部特征融合模型,实现推理精度与效率的平衡,为大规模知识推理提供解决方案。
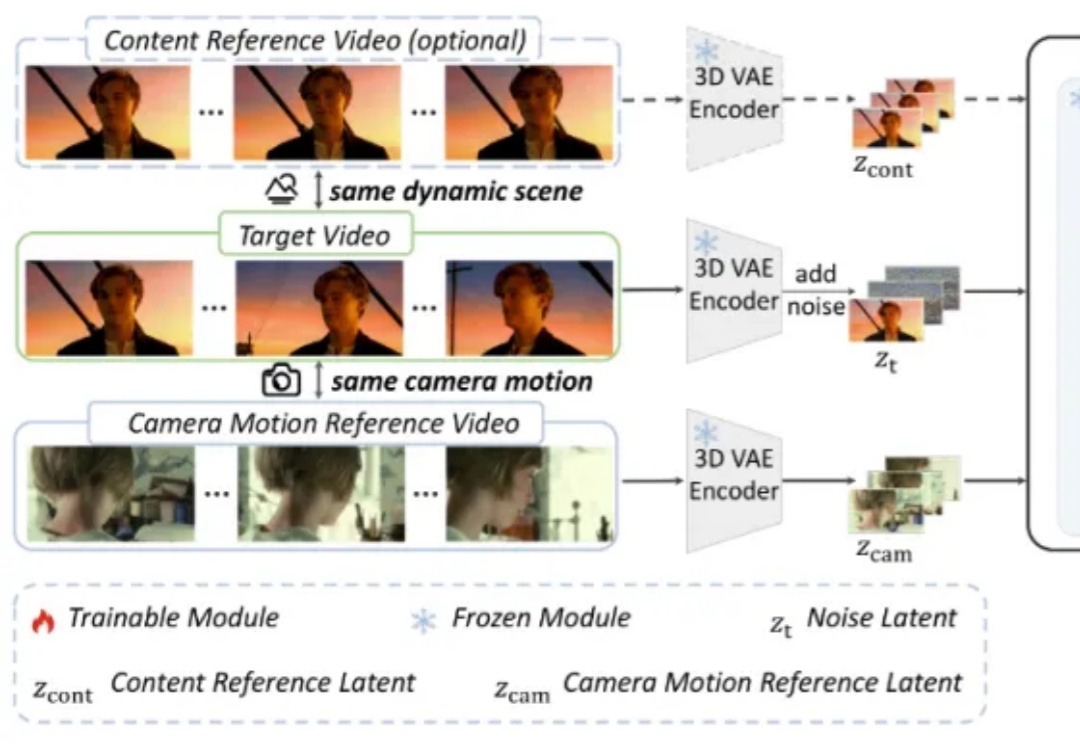
作为视频创作者,你是否曾梦想复刻《盗梦空间》里颠覆物理的旋转镜头,或是重现《泰坦尼克号》船头经典的追踪运镜?
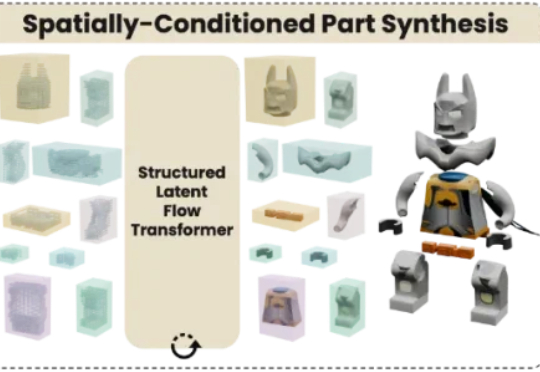
在3D内容创作领域,如何像玩乐高一样,自由生成、编辑和组合对象的各个部件,一直是一个核心挑战。香港大学、VAST、哈尔滨工业大学及浙江大学的研究者们联手,推出了一个名为 OmniPart 的全新框架,巧妙地解决了这一难题。该研究已被计算机图形学顶会 SIGGRAPH Asia 2025 接收。
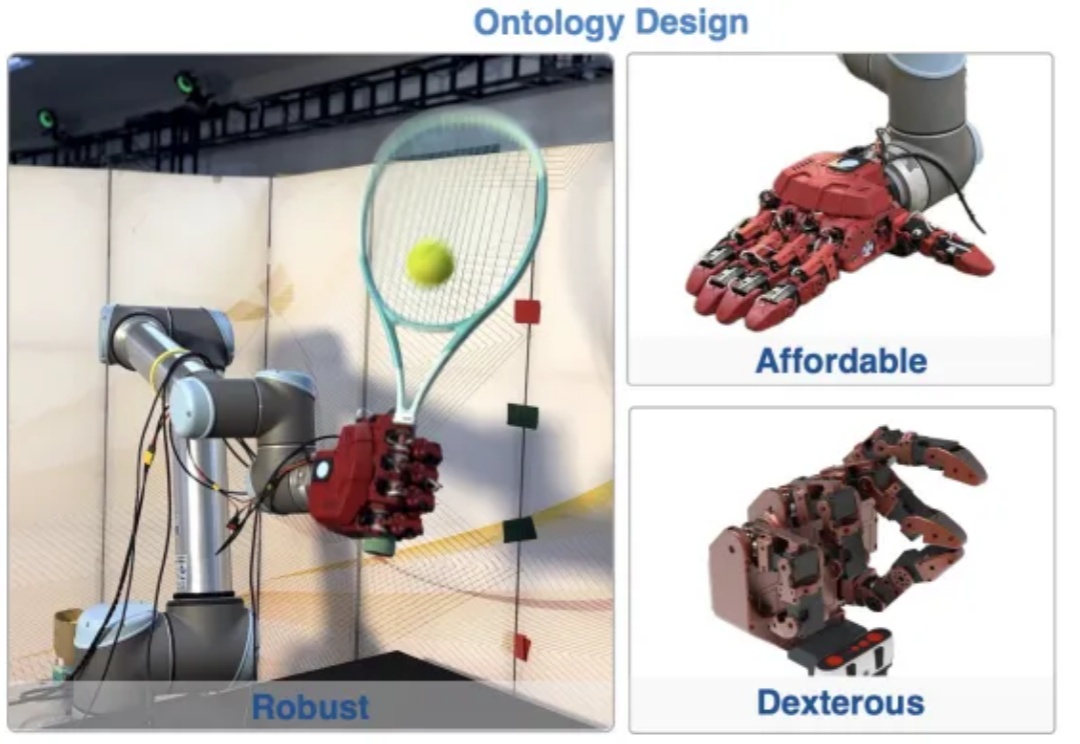
在最近的一篇 NeurIPS 25 中稿论文中,来自中山大学、加州大学 Merced 分校、中科院自动化研究所、诚橙动力的研究者联合提出了一个全新开源的高自由度灵巧手平台 — RAPID Hand (Robust, Affordable, Perception-Integrated, Dexterous Hand)。
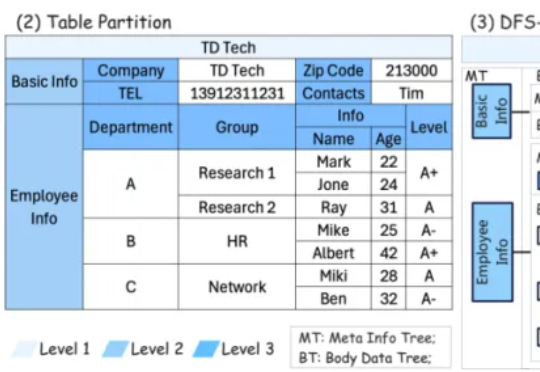
来自上海交通大学计算机学院、西蒙菲莎大学、清华大学、中国人民大学的合作团队,带来基于树形框架的智能表格问答系统(ST-Raptor),其不仅能精准捕捉表格中的复杂布局,还能自动生成表格操作指令,并一步步执行这些操作流程,最终准确回答用户提出的问题 —— 就像给 Excel 装上了一个会思考的 “AI 大脑”。

嗨大家好!我是阿真! 今天尝试最近很火的国内首个音乐创作智能体Tunee,通过对话就能创作音乐,我愿称之为更适合中国宝宝体质的音乐Agent。