
超94%类别第一!3D点云异常检测与修复新SOTA | ICCV'25
超94%类别第一!3D点云异常检测与修复新SOTA | ICCV'253D点云异常检测对制造、打印等领域至关重要,可传统方法常丢细节、难修复。上海科大与密歇根大学携手打造PASDF框架,借助「姿态对齐+连续表征」技术,达成检测修复一体化,实验显示其精准又稳定。
来自主题: AI技术研报
7986 点击 2025-10-28 09:34
 搜索
搜索
3D点云异常检测对制造、打印等领域至关重要,可传统方法常丢细节、难修复。上海科大与密歇根大学携手打造PASDF框架,借助「姿态对齐+连续表征」技术,达成检测修复一体化,实验显示其精准又稳定。
美团,你是跨界上瘾了是吧!(doge)没错,最新开源SOTA视频模型,又是来自这家“送外卖”的公司。模型名为LongCat-Video,参数13.6B,支持文生/图生视频,视频时长可达数分钟。
HuggingFace 与牛津大学的研究者们为想要进入现代机器人学习领域的新人们提供了了一份极其全面易懂的技术教程。这份教程将带领读者探索现代机器人学习的全景,从强化学习和模仿学习的基础原理出发,逐步走向能够在多种任务甚至不同机器人形态下运行的通用型、语言条件模型。

知识图谱推理是人工智能的关键技术,在多领域有广泛应用,但现有方法存在推理效率低、表达能力不足、过平滑问题等挑战。中科大研究团队提出DuetGraph,采用双阶段粗到细推理框架与双通路全局 - 局部特征融合模型,实现推理精度与效率的平衡,为大规模知识推理提供解决方案。
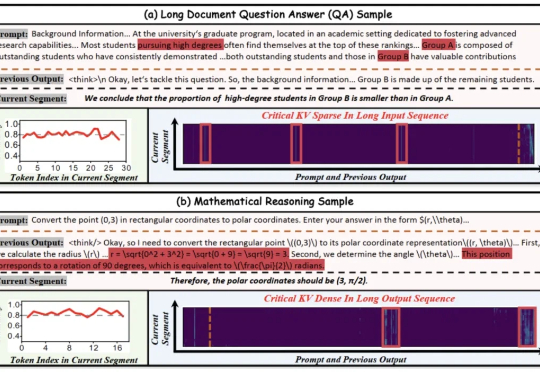
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。

具身智能落地迈出关键一步,AI拥有第一人称与第三人称的“通感”了!
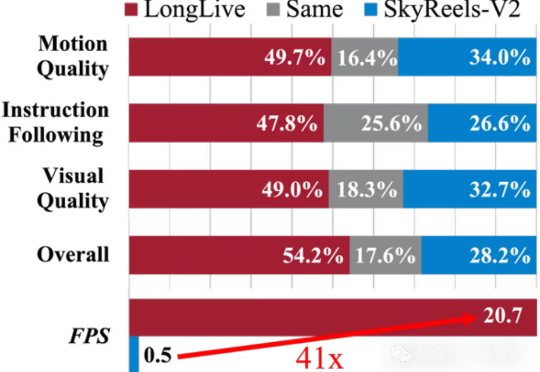
AI拍长视频不再是难事!LongLive通过实时交互生成流畅画面,解决了传统方法的卡顿、不连贯等痛点,让普通人都能轻松拍大片。无论是15秒短片还是240秒长片,画面连贯、节奏流畅,让创作变得像打字一样简单。
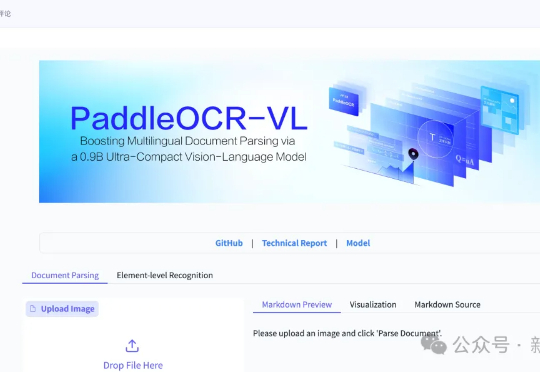
百度登顶全球第一!最新模型「PaddleOCR-VL」以0.9B参数量,在全球权威榜单OmniDocBench V1.5中以92.6分夺得综合性能第一,横扫文本识别、公式识别、表格理解与阅读顺序四项SOTA。
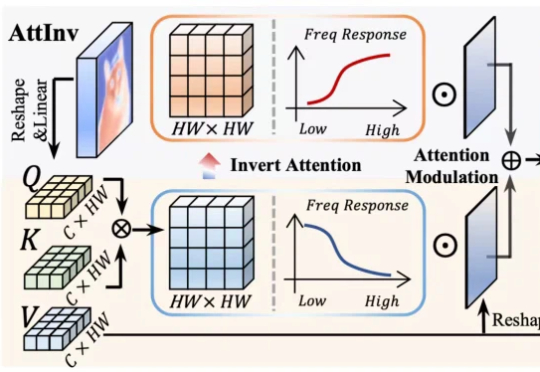
针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。
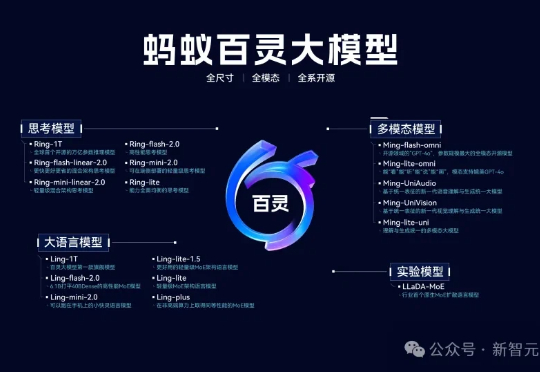
在AI浪潮中,蚂蚁集团重磅推出万亿参数思考模型Ring-1T,不仅在数学竞赛上刷新开源SOTA,还在逻辑推理和医疗问答中脱颖而出。实测显示,其推理能力直逼闭源巨头,开源AI迈入万亿参数时代。