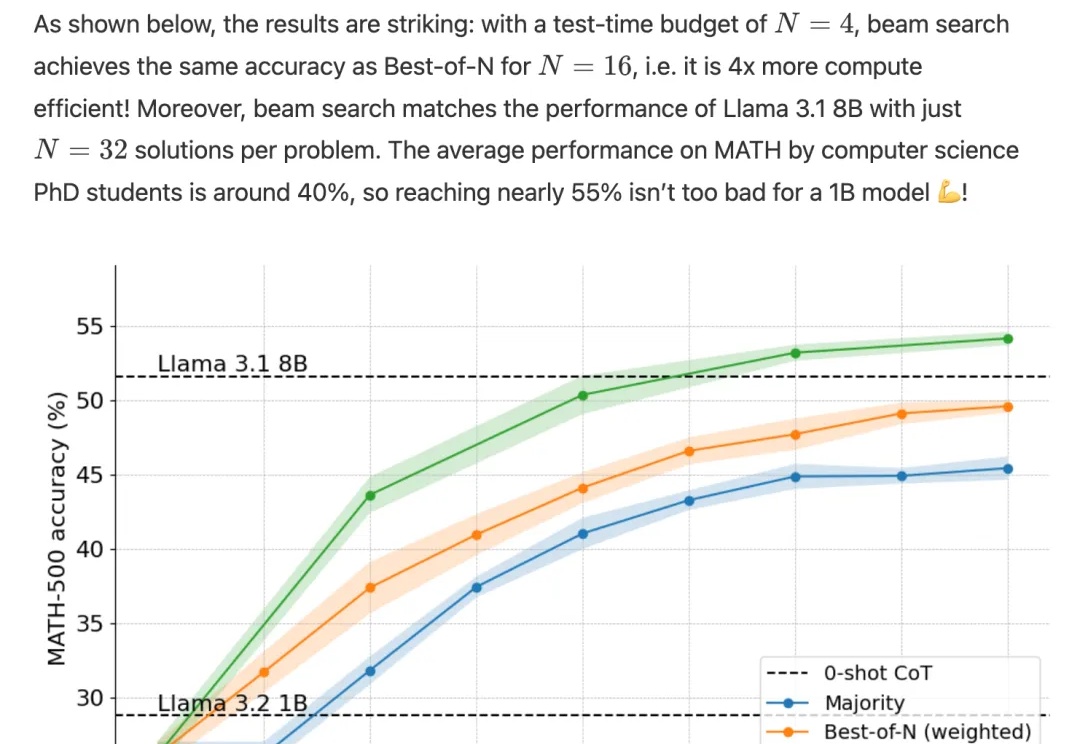
开源Llama版o1来了,3B小模型反超80B,逆向工程复现OpenAI新Scaling Law
开源Llama版o1来了,3B小模型反超80B,逆向工程复现OpenAI新Scaling Lawo1完整版公开仅10天,Scaling Law新范式就被逆向工程复现了!
来自主题: AI技术研报
7184 点击 2024-12-17 17:12
 搜索
搜索
o1完整版公开仅10天,Scaling Law新范式就被逆向工程复现了!

Ilya「预训练结束了」言论一出,圈内哗然。谷歌大佬Logan Klipatrick和LeCun站出来反对说:预训练还没结束!Scaling Law真的崩了吗?Epoch AI发布报告称,我们已经进入「小模型」周期,但下一代依然会更大。

在Ilya探讨完「预训练即将终结」之后,关于Scaling Law的讨论再次引发热议。
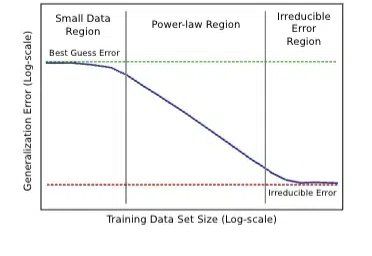
Scaling Law不仅在放缓,而且不一定总是适用! 尤其在文本分类任务中,扩大训练集的数据量可能会带来更严重的数据冲突和数据冗余。

「Scaling Law」和「打脸时刻」,绝对是2024年科技智能领域的年度关键词。
支持大模型一路狂飙的 Scaling Law 到头了? 近期,AI 圈针对 Scaling Law 是否到头产生了分歧。一派观点认为 Scaling Law 已经「撞墙」了,另一派观点(如 OpenAI CEO Sam Altman)仍然坚定 Scaling Law 的潜力尚未穷尽。
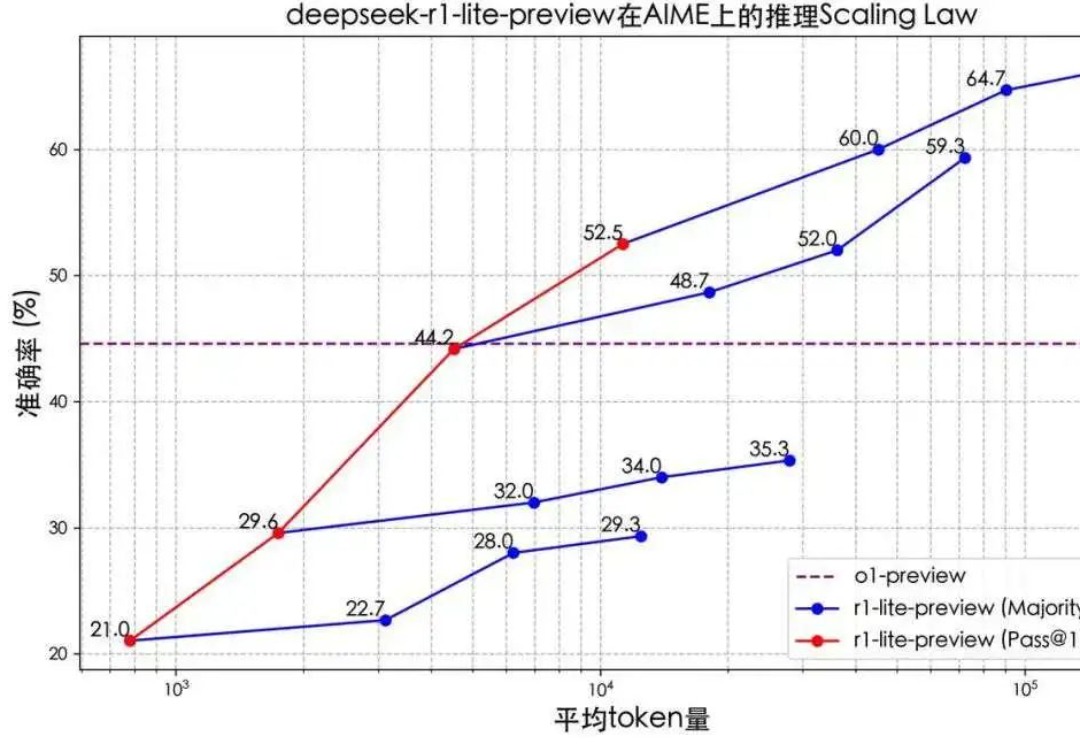
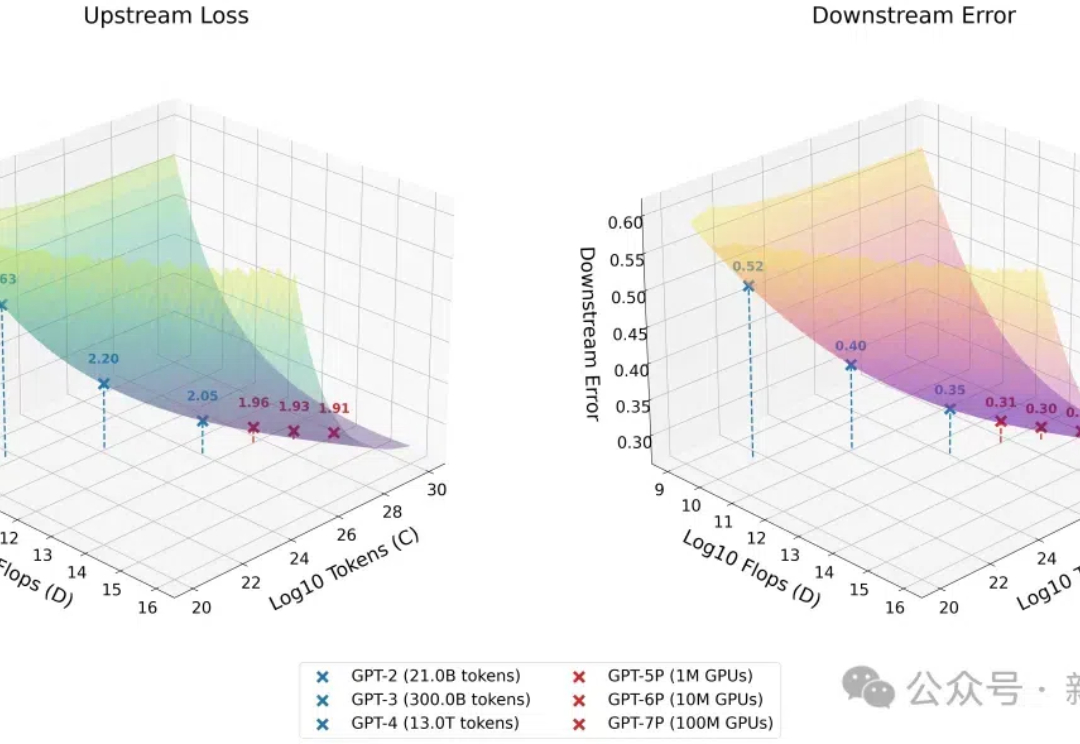
ChatGPT诞生的第二年,OpenAI和国内的一众企业正在试着“抛弃”它。 在Scaling Law被质疑能力“见顶”的情况下,今年9月,OpenAI带着以全新系列命名的模型o1一经发布,“会思考的大模型”再度成为焦点。
世界上第一个被人类骗走近5万美元的AI,刚刚出现了!巧舌如簧的人类,利用精妙缜密的prompt工程,成功从AI智能体那里骗走了一大笔钱。

环境持续变化,时代总在迭变,“商业之王”们紧随时代浪潮,坚持创造,谋求新动能。立足中国经济大转型的当下,WISE2024 商业之王大会,一同发现真正有韧性的“商业之王”,探寻中国商业浪潮里“正确的事”。
什么?Scaling Law最早是百度2017年提的?! Meta研究员翻出经典论文: 大多数人可能不知道,Scaling law原始研究来自2017年的百度,而非三年后(2020年)的OpenAI。