
大模型“降智”真相,找到了
大模型“降智”真相,找到了今天,智谱发布了一篇名为《Scaling Pain:超大规模Coding Agent推理实践》的技术报告,披露了GLM-5系列模型在Coding Agent场景下遇到的推理基础设施挑战与对应解法。
来自主题: AI技术研报
9996 点击 2026-04-30 13:52
 搜索
搜索
今天,智谱发布了一篇名为《Scaling Pain:超大规模Coding Agent推理实践》的技术报告,披露了GLM-5系列模型在Coding Agent场景下遇到的推理基础设施挑战与对应解法。

就在这一背景下,银河通用联合清华北大英伟达等众多机构联合发布了跨本体「隐式世界-动作基础模型」LDA-1B,将目光投向了具身智能 Scaling Law 的这个终极命题:如何让模型有效利用互联网规模的异构数据。

AlphaGo 之父 David Silver 创办的 Ineffable Intelligence 获 11 亿美元种子轮,创欧洲融资纪录,估值达 51 亿美元。这家公司押注强化学习和自我经验学习,试图挑战依赖 Scaling Law 的大模型主线。

具身智能的Scaling Law停滞了吗?

4 月 10 日晚,灵初智能发布了大模型、数据集与合作计划:包括策略模型 Psi-R2、世界模型 Psi-W0,以及总规模近 10 万小时的人类操作数据。它想回答的问题也很直接 —— 当真机数据不再是唯一解,机器人还能靠什么继续 scaling?

具身智能独角兽Generalist,刚刚推出了最新的研究成果——新模型Gen-1。在包装手机和折叠纸箱这些精细活儿上,它把机器人的成功率从64%硬生生拉到了99%,几乎告别了手残职业病。

具身数据层的全球竞赛正在迅速升温。NVIDIA Research在2026年发布EgoScale数据与训练框架,在Ego-centric人类操作视频上训练VLA模型,用 20,854小时带动作标注的第一人称人类视频,观察到数据规模和验证损失之间接近对数线性的scaling law。1X收集人类第一视角及家庭行为数据,通过 Sunday项目采集百万小时级家庭场景视频。

三周前那个疯狂传言,如今被Mythos彻底印证?Anthropic或已完成史上最大规模训练,新模型性能或将达到预期的2倍,翻倍碾压Scaling Law!一场颠覆性变革正在降临,算力、能源成为终极筹码,创业公司恐遭毁灭性降维打击!

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大
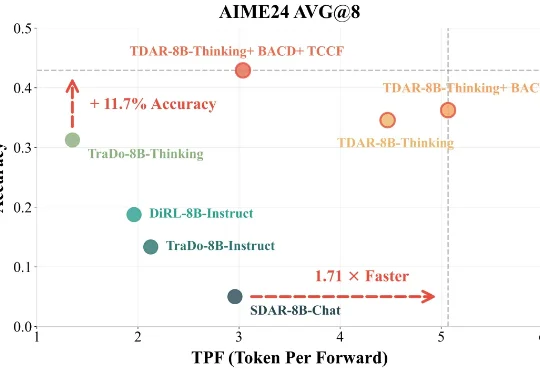
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码